Big Data - Plant gene expression workshop 4
Andrea Harper

Introduction
Aims
In this workshop, we will start to investigate the function of some of the markers which we have found to be associated with the glucosinolate trait in order to identify a likely causative gene. The examples we will work through in the workshop are from the small expression dataset. Don’t forget that if you choose to do this analysis for your report, you will need to work though the workshops with the complete dataset which you can find here, or in the Data Sets tab in the VLE.
Learning Outcomes
By doing this practical and carrying out the independent study the successful student will be able to:
- retrieve sequence data for genes of interest from large datafile
- identify their closest sequence match to arabidopsis genes using BLAST
- investigate regions of the Arabidopsis genome and candidate gene functions using the TAIR database
Getting started
Start RStudio from the Start menu
{kind=link}
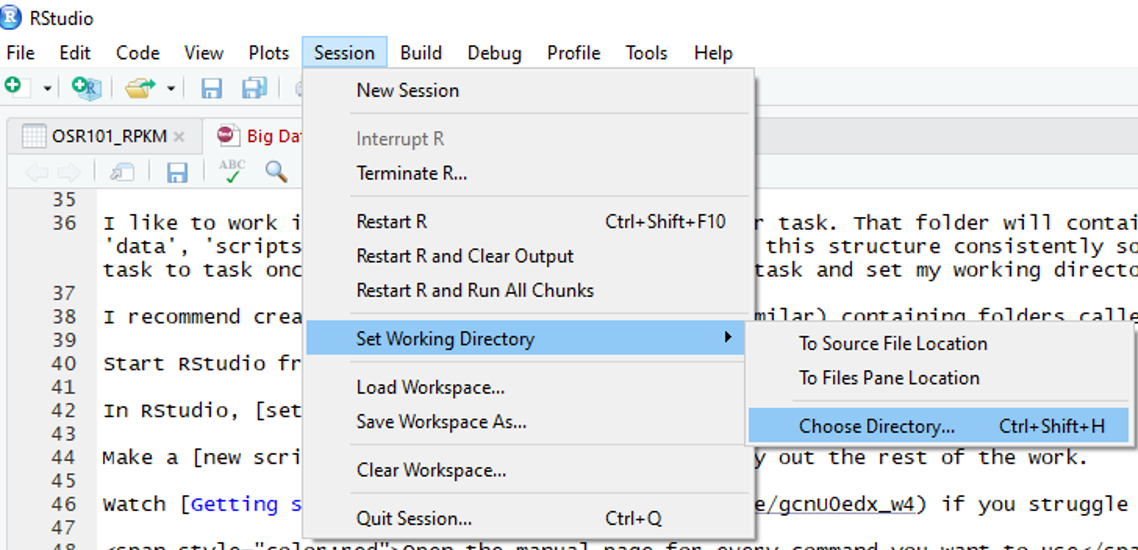
In RStudio, set your working directory to your scripts folder
{kind=link}
Selecting nucleotide sequences for genes of interest
Open the final results file you created in workshop 3. We’re also going to set an important option in R (stringsAsFactors) - don’t miss this out!
options(stringsAsFactors = FALSE)
final <- read.delim("Final results.txt", header=T)In workshop 3, we calculated the false discovery rate for this dataset, and only two markers had a p value that passed it. Let’s download the nucleotide sequence for these genes from a list of sequences.
Read in the list of sequences - this is a LARGE file, so may take a few mins…
seqs <- read.delim("http://www-users.york.ac.uk/~ah1309/BigData/data/genes.txt")Take a look at the first five rows
seqs[1:5,]## Gene
## 1 A_JCVI_40613
## 2 A_JCVI_16890
## 3 A_JCVI_4085
## 4 A_JCVI_20894
## 5 A_JCVI_13033
## Sequence
## 1 CCACGCGTCCGCGGACGCGTGGGTCGACCACCATGCATCAAACAATTCACGCCTCTTAGCTCCATAAGCTTCTTTATTATGTTTTAGGTATTATAACATTACATGAATATATAAAAAGCAAAATTTGGAGTCTACGTGAAAAAACATGAAAACACCTTGCAGCTATGTGGGTAAGACCCAAGAGTGTTTTTCGATAAGTCTCATATTCAGATGCATCAGAGTTCTCATCAAAAGATCTATTTCTTTCTTATCTGATTAGAAAATTTCCTTTGAAAATTTTCTTTCTTTAAGTATATCTCTCTCTATATATATTTGCTTTCTTGGGTGTTTTCAGTCTTTCAGAGGTTTTATATATATATATATATGAAACTTTGCCTACTAGTGTGCATATATAGCGACTAAAAATGTCAAGAAAACCGTGTTGTGTCGGAGAAGGGCTGAAGAAAGGGGCATGGACCACCGAAGAAGATAAGAAACTCATCTCTTACATCCACGAACATGGAGAAGGAGGCTGGCGCGACATTCCCCAAAAAGCTGGGTTAAAAAGGTGTGGAAAGAGTTGTAGACTGCGTTGGACTAACTACCTAAAACCTGATGTCAAAAGAGGCGAGTTTAGCTCAGAGGAGGAACAGATTATTATCATGCTTCATGCTTCTCGTGGTAACAAGTGGTCGGACATAGCGAGACATTTACCTAGAAGAACAGACAATGAGATCAAAAACTACTGGAACACACATCTCAAGAAGCGTTTGATTGAACAGGGTACTGATCCCGTGACTCACAAGCCACTAGCTTCTAATACAAACCCTACCTACAGTACCTGAGAATTTGCATTCCCTAGATGCATCTAGTTCCGACAAGCAATACTCCCGGTCAAGCTCAATGCCTACCATGTCTTGTCCTCCTTCCTCCTGTTTCAACACGGTTTTCGAGAATACCAGCAAAGATGGGACACCAGTTCATGAGGACGATTCCTTGAGTCGCAAGAAACGTTTTAAGAAATCAAGTTCTACATCAAGGCTTTTGAACAAAGTTGCTGCTAAGGCCACTTCCATGAAAGAAGCTTTGTCTGCTTCCATGGAAGGTAGCTTGAATGCTAATACAAGCTTTTCCAATAGCTTCTCTGAGCAGATTCGCAATGAAGAGGATAGTTCTAATGCATCCCTGATAAATACTCTAGCTGAATTTGATCCCTTCCTCCAAACAACGTTGTACCCTGAGCATGAAATGAATACTACTTCTGATCTCGATAGATCAGGACTACTTCTCACATT
## 2 TAGGTTGAGTTTTCCTTGGCGGAGATATGTCTCAGAATCTGAATCAGCCGAGGTCTACAATGAGAAAGTTTCTATAATGGAAGTGCTAAAGAAAGCCAACTCTTTTATTCCTCATGTGACTCTCTCAAGTACAATCTTAGCTCTTCTCTATCCACCTTCTTTCACATGGTTCAAGCCAAGGTACTTTGTGCCTGGCTTAGGGTTCATGATGTTTGCTGTTGGAATCAACTCTAACGAACGAGACTTTCTTGAAGCTCTTAAAAGACCAGACGCTATTTTCGCCGGTTACATCGGACAACACCTGATAAAACCTCTCTTAGGTTATATGTTCGGCTTAATAGCTGTCTCCCATTTCAAGCTACCTACTCCTATAGGTGCCGGAATCATGTTGGTATCATGTGTTAGTGGAGCTCAACTATCGAATTACACAACTTTCTTGACCGATCCTTCACTCGCGCCGCTTAGTATTGTCATGACATCGATCTCAACAGCTACCGCGGCACTCGTTACACCCATGCTTTCTCTCTTGCTCATTGGTAAAAAGCTTCCCGTTGATGTGGTTGGGATGGTCTCTAGCATTCTCCAGGTCGTGGTTACACCAATTGCCGCAGGACTTCTTCTGAACCGGTTAGACACAAGCTCAATCAATTAGAAATGCATGCATGTCAGA
## 3 CCATCCCAATGGTTATAGTTTCTCCCAAGAGAGAACGCAAAGATTGGCTCGTTGCAGATGTTTGTGAGTAATGTTGGAACTTGTGAAGATATGGGATACGGAGTCTTCCCTGTCGATCAGGTTCATAAGATCTCGGTTCTAGACATTAGGCTTGCTAATGCGGATCGTCACGGTGGTAACATTTTGGTTAGCCGAGATGGAAATGATGGTCAGATCGTGCTTACACCAATCGACCACGGCTATTGCTTTCCAAATAAGTTTGAAGACTGCACATTCGAGTGGCTATACTGGCCTCAAGCAAAAGAGCCATACTCTTCAGAGACTCTTGAATACATCAAAGCCTTGGACGCTGAGGAAGACATTGAGCTTCTGAGGTTCCACGGTTGGGAGATTCCGCCTTCATGCGCCCGTGTCTTCCGCATCTCCACCATGCTTCTCAAGAAAGGTGCTGCGAAGGGTCTCACACCTTTCGCCATCGGAAGCATTATGTGCAGAGAAACACTCGAGAAAGAATCTGTGATCGAACAAATCATCTATGATGCAGAAGCAATGTGGTCCCCAGAGACAACAGAAGAGGAGTTTATCAGCACCGTCTCTGCTATTATGGATCGATGCCTCGACCAGTGTTCTCTGAACTGAAAATATTTATCACACAGCCCCAAGATTCCACTCATGACTGTGTATATCCGGTGTCCATAACAATAAATAAGCGTCACTGTCTTTGAACCCAATCTTAGCTTTTGTAAACAGTGGTTTGGTAATGATGATTGGGTTTATAGAATCGTCATGCTTCTGTGGTTTGTTGGGTTAAATAACGTTCCTGTGTACTTATTTCAGTTCTGGATGATGAACAAGTCAGTATACTACG
## 4 CCCCGGCCGAGAAGTGGAAGTGACCATCTCATCAGCAAAGAATATCAAGAACGTGAACAGGGCAAAAGGCCCAAAAAAACCAAAACCCCCCCATAGGAACAAACCCAAAAAAAAATTTCCCCCCAAGACCAAAAAAAGGGAAAAACACGTCCCCCCCGGGAACCAACAATTTTCAAACCCTTTCCCCCCGGGAAAAAAAAAAAAAAAAAAAAAAAAAACTTTAAACAAACGGGGCACACGGGGGGGGAAAAGAAAACAAAAACCCCCAAACGGCCCCCCCAAATCAAACCCCCGCGATGTCATCGACAATGCTCGCTTCGGCCTCCCCGGGGAAAAAACCCTCAAACCCAAACCCCCCCCCGGCACACCCCACCGCAAACTCCGCCTCACCGTCACCGTCAGAGAGCCTCGGTATCAACCGGCTCCGGGTTCTTACCACGCGCCGCCATACGGTTATACTCACGCGCCACCGCAACCTGTTTATGGTGAACCATACACTCACGCGCCGCCGCAACCCGTTTACGATTACCCTTACGCGCCACCGCAGCCGTACGGAACCGCTTCGTACGGACAGTCAGGTTATACGGCGGAGAAAGAGAAAGGGAGCAAGTTCGGTGGGATGGGGACGGGGCTGGCGGTTGGGGCGGTTGCCGGAGTTCTTGGTGGGGTGGCGTTAGCGGAGGGATTGGATGAGGTGGAGGACGACATCGCTGAGGAAGCAGCGGAGGATGTGGAGGATGATGATGCCGGCGAGGACGACGAGGACTTTTAATCGTGCTGTTTAATCATATTCAATAATTATATATGCCGACAAGTCCTCATTGATTGTCGACATCTATCA
## 5 GAATTAGTTAATAAGAAATCGTGTTAAAATAATATAGATGCTGCTCAAACATAATGGGGTACACAGGAATTAATTATAGCTCTCCAACACTTGCTTCTGCGATCAGCAACCTCACTCCTGCGTTTACCTTCTTGCTCGCCATCCTTTTCAGGTTGTTGGCGAACCCCCCTTAAAAAATCCGTTTAAAACAACAAATTCCCAAAAAAACAACCGCCCAACGAACCGAATTGGGCCCCCAAAAAATCCTTGGGGGTTGGTTGCAGGATGGAGAGTGTATCTTTCAAGAGAACAAGTAGTGTAGCTAAAATGTTAGGAACTGTAGTTTCCATTGGAGGAGCATTTATAGTGACTCTTTACAATGGACCTGTGGTGATCTCTATGTCACCACCATCTATATCTTTGAGATCACAGTCAACAAACCATAATTGGATCATTGGCGCTGCGTTCCTTTCCGTCGAGTATTTCATGGTTCCTTTGTGGTACATTGTTCAGACTCAAATCATGAGAGAGTATCCATCCGAGTTCACCGTTGTTTGTTACTATAGCTTAGGCGTGAGCTTTTGGACCGGGCTTGTCACCTTGTTCACTGAAGGGAGTGACTTGAATGCATGGAAGATAAAACCAAATATAGCTTTAGTGTCAATCGTTTGCTCGGGAGTTTTTGGATCTTGCATAAACAATACAATCCATACGTGGGCGTTGCGGATCAAGGGGCCTTTATTTGTTGCAATGTTCAAGCCTCTGTCGATTGCTATTGCCGTTGCAATGGGTGTGATCTTCCTCCATGATTCTCTCTACATTGGCAGCTTGATCGGGGCAACGGTAATAACGACCGGTTTTTACACTGTGATGTGGGGCAAAGCTAAGGAAGCGGCCATGGTCGAAGATGACAACAAGGCTAACAACGAGGATGCCACCAACGAAGCTGACCTTGATTCTCCATTAGCTTCACAGAAGGCTCCTCTCTTGGAAAGTTACAAGAACGACGAGCATGTCTAAGTATTATCTACTAGTCACGATAGTTCTCTATACATATGTGTATGTGAAAGTTTCACATGTGAACGTCTTTATAATTTATTTGAAGACGCAAATGTGATATTTAATTTTAGGAATCAAGTCTAATAACATATCATATCAAAATTMake the rownames the same as the Gene names
rownames(seqs) <- seqs$GeneNow take a look at the top of your results table:
final[1:5,]## Gene Graph Position Df Sum.Sq Mean.Sq F.value
## 1 A_JCVI_10238 1 528 1 11408.052 11408.052 14.986357
## 2 A_JCVI_10398 2 655 1 10306.477 10306.477 13.165687
## 3 A_JCVI_10097 1 8093 1 7299.818 7299.818 8.671854
## 4 A_JCVI_10299 2 4320 1 5695.814 5695.814 6.522668
## 5 A_JCVI_10155 1 1837 1 5091.926 5091.926 5.753102
## P.value R2 Intercept Gradient logP Rank FDR
## 1 0.0003092814 0.2271130 7.503403 3.7931699 3.509646 1 0.02257754
## 2 0.0006596128 0.2051827 87.651634 -6.2952872 3.180711 2 0.02407587
## 3 0.0048576830 0.1453257 16.374764 2.4834231 2.313571 3 0.11820362
## 4 0.0136817492 0.1133930 75.122442 -0.1349702 1.863858 4 0.24969192
## 5 0.0201550254 0.1013707 12.505862 2.5569946 1.695617 5 0.29426337We could pull out the interesting gene names in a few ways. We could take the top few gene names…
top3genes <- as.vector(final$Gene[1:3])
top3genes## [1] "A_JCVI_10238" "A_JCVI_10398" "A_JCVI_10097"…Or just the top gene name, since we know it is the only one passing the Bonferroni multiple test corrections…
topgene <- final$Gene[1]
topgene## [1] "A_JCVI_10238"… But you don’t even have to know which rows you want if you use the subset function. Let’s try it by selecting only the gene names with an FDR-adjusted p value of less than 0.05…
FDRgenes <- subset(final$Gene, final$FDR<0.05)
FDRgenes## [1] "A_JCVI_10238" "A_JCVI_10398"Now we know which gene or gene names we want sequence data for, let’s subset the sequence file to only include those genes. Let’s start with the ones that pass FDR…
topseqs <- seqs[FDRgenes,]
topseqs## Gene
## A_JCVI_10238 A_JCVI_10238
## A_JCVI_10398 A_JCVI_10398
## Sequence
## A_JCVI_10238 TCTCCTCCCCCATCGTTTCCTCGGGCTACATCTCCCGCCGTCTCTCCCGTTCCGCCCTTTTTATCTTGGTTGGATGGGCACATCATCTGGCTCCAATCACCCTCACCAGATGCTACCTCCACGTCATCAGCTCCGAACCGGAGCCCTCGAAACAACTCTCTCACTCGTCTCACACGACGGCCATGAGCCACGTTCCAACAACAACTCTGACGCCATCCGCGAGTCCCCAGCCGAGAGCGCCAGCTCTCAAAAAACATGGCCGCTCGCTGATCCCGTAACAGCAAAGAAGAAGACGGCGGTGAAACAAAAGACAGAGCCTGAGGAACAACAGGAACAACAACAACAACAAACCGTGATGCACCACGTCTCCAGCGCAGATAAAGTATCGGTCCGAGACATCGCTAGAGAAAGAGTGGAGATAGTCGCAGAGAGAATGCACAGGTTACCCGACGAGTTTCTCGAGGAGTTGAAGAATGGTCTTAAGAACGTTCTCGAAGGAAACGTCGAGGAGTTCGTGTTCTTGCAGAAGCTTGTTCAGAGCAGATCCGATCTGAAGAACCCCGCAACGTTACTCAGAGCCCACCGTTCCCAGCTTGAGATCCTCGTAGCGATAAACACTGGAATCCAAGCGTTCTTGCACCCGAACGTAACTCTCTCTCAGTCATCTCTCGTGGAGATATTCTTACACAAGAGGTGCAGAAACATACCCTGCCAAAACCAGCTACCAGCCGACGGCTGCCGCTGCGACGTTTGCGCCGCCAGGAAAGGCTTCTGCAGCCTCTGCATGTGTGTGATCTGCAACAAGTTTGATTTTTCAGTCAACACCTGCCGCTGGATAGGGTGCGACTCGTGTTCACACTGGACTCATACGGATTGCGCTATAAGAGATGGACAGATCACTGCAAAGAACGCGTCGGGTCGTTCTGGAGAGATGATGTTCAAGTGCAGGGCGTGTAACCACGCTTCTGAGCTGATTGGGTTTGTTAGAGATGTGTTTCAGCACTGTGCGTCGAACTGGGATAGGGAGTGTTTGGTGAAGGAGCTGGATTTTGTTAGTAGGATCTTCCGAGGAAGCGAGGATCAGAGAGGTAGGAAGCTGTTCTGGAAGTGTGAGGAGGTTATGGATAAGATTAAAGGTGGCTTGGCGGAGACAACGGCTGCTAAACTGATA
## A_JCVI_10398 TCTAGTTGGTCAGTTGAAAGGTGAATTTGATGTGCAGACTACATTTGAGGGTGACAATAATGTATTGATGCAGCAGGTGAGCAAAGCACTGTTTGCTGAGTATGTGTCGTGTAAGAAGAGAAACAAACCTTTCAGAGGGTTGGGATTGGAGCACATGAACAGTTCTCGTCCTGTATTGCCAACTCAGCTCTCATCTTCTACCCTCAGATGCAGCCAGTTTCAGAAAAATGTGTTCTGCTTAAGAGAAAGAGATCTTCTAGAAAGATTCACTTCTGAAGTTGCGCAGCTTCAAGGGAGGGGAGAGAGTCGAGAGTCCTCTTTCCTCGTGAATCATGAACTTGCTGAGGACTTAGGCAAAGCTTTCACAGAGAAAGCAATACTGCAAACTATTCTGGATGCTGAGGCCAAACTACCTGCTGGCTCAATGAAGGATGTGTTGGGTCTTGTAAGATCAATGTACGCATTGATCAGCATTGAAGAAGATCCGTCGTTCTTGAGATACGGTTACCTCTCAAGGGACAACGTTGGAGATGTGAGGAGAGAGGTTTCTAAGCTCTGCGGAGAGCTTAGCCTTCCGGGGTTTGCCTTGTTAGTTTCTTTCGGGTTTCCGGCGGGTTTTTTGGGCCCATTTGGTTTCACTTGGTTGGAGGCCACGGTTTGTTTTTCGTTTTATTTTCTACGAATACTTTTTTCTAATAATCCTCCTCGTTTTTTTTTTTTTTTTTTTTTTCTGAAAACTGTTGTTTTATGCTCTTGGTAATAAAACGGGGTAATGTAATATGTATCCACGGTTTAGTCTTTTACCCAAACTGGTCCAGATCGGGCCGGATCTGATATCTCAGGGGCTCTAAACATTCTTTCAYou can now save this as a text file
write.table(topseqs, "topseqs.txt", quote=F, sep="\t")Gene function
Open your topseqs file in MS Excel, and copy a sequence for one of your genes of interest. Let’s see what sort of gene it is by performing a BLAST alignment on the NCBI Blast page here.
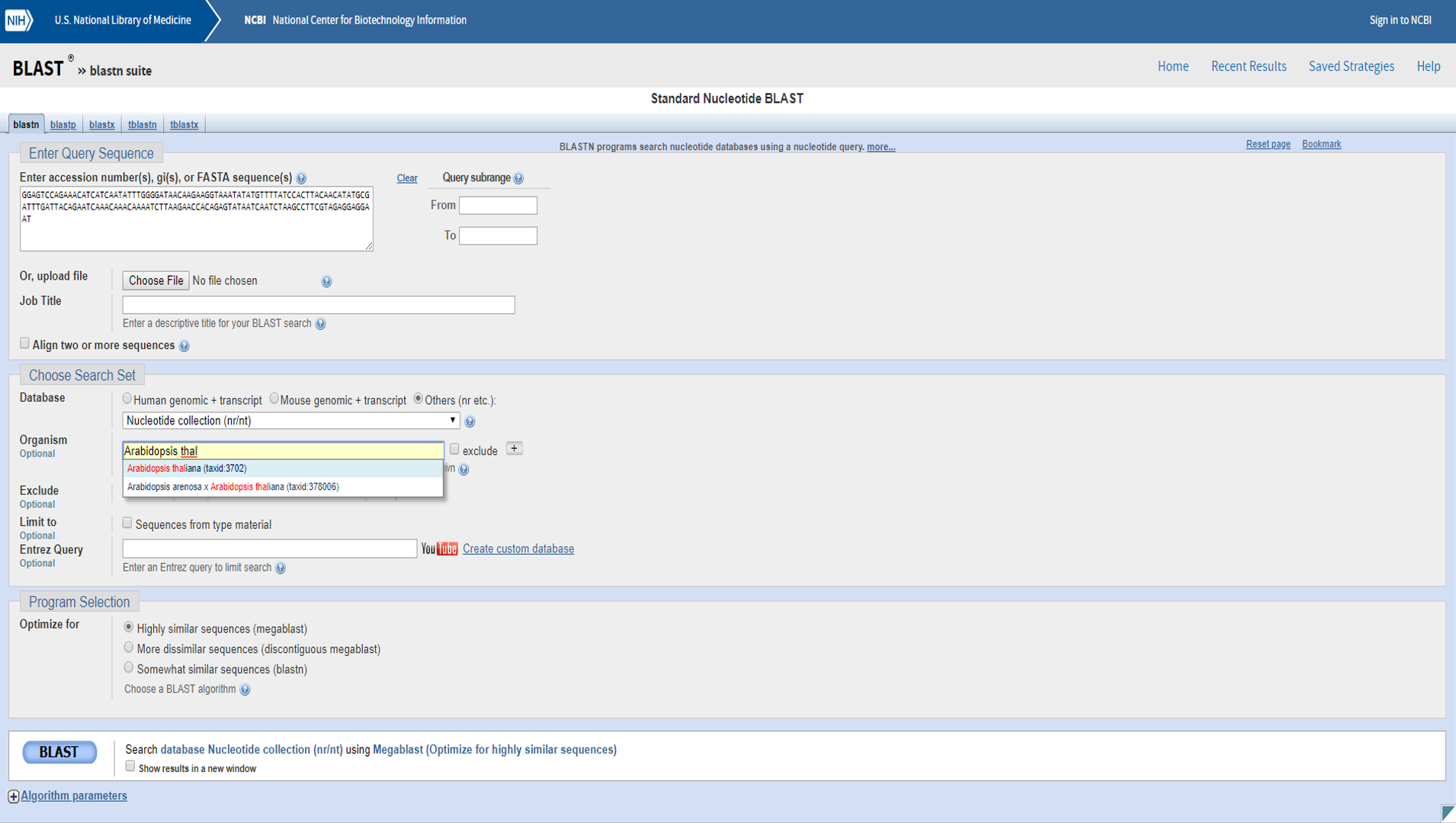
We can try different types of BLAST, but we should start with a nucleotide BLAST, so select that option. Nucleotide BLAST looks for similar nucleotide sequences in the dataase.
Paste your sequence into the search box, and type “Arabidopsis thaliana” in the Organism box. Select the “Arabidopsis thaliana (taxid:3702)” option. Arabidopsis is the most studied plant model, and is related to Brassicas, so is probably our best bet to identify the functions of our genes. You can leave all of the other options on their default settings and press BLAST.
{kind=link}
Did you get any significant results? If not, try a different setting. You can use the “edit and resubmit” button to go back.
Try the third tab on the search window called blastx. Instead of comparing nucleotide sequences directly, BLASTx translates the sequence into the amino acids that make up the protein, and them looks for similar proteins in the database. Don’t forget to select an organism!
If this doesn’t give you a hit either, try deleting the Arabidopsis option in the Organism box. This will allow BLAST to search through all of the species in the database. This may give you some idea of the kind of gene you have, but depending on the organism, may not give you as much functional information. You might need to view the annotations for the top few results to get the information you want.
If you get a hit to Arabidopsis with any of the searches, click the Accession link in the descriptions box. This will take you to a page which tells you more about that gene.

Look for a gene name - it will be something like “At3g42130”. The name refers to the species (Arabidopsis thaliana), the chromosome (which would be 3 in this case), and the position on that chromosome (42130). This gene code can also be used to find out more about your gene.

Let’s use another website called TAIR which stands for The Arabidopsis Information Resource
Try putting your gene code into the search box at the top of the homepage. Click on the locus name to learn more about the gene. Look for a potential link to glucosinolate biosynthesis.
*PRO TIP:*
Candidate genes could be anywhere within “peaks” of association (where there are lots of markers all in the same place in the genome). Try finding the top gene in the peak and putting it into TAIR, click on the locus, and then on the map detail. This will open the genome browser, which will allow you to look at all the other genes around it.

Change the genome distance displayed to 40kb, and hover or click on each gene in turn to learn more about it.

Could any of the genes be good candidates for controlling glucosinolate content? Look for some papers on glucosinolate biosynthesis in Arabidopsis like this one to give you some clues. You can also try typing “Glucosinolate” into the TAIR search box, although you should be careful, as it might not return all of the genes involved in the pathway!
For next time
Try completing these tasks using your results from the full dataset. Can you find any likely candidate genes from your analysis of the full dataset? In case you need it, the full dataset is here.