PhD Topics
If you are interested in doing a PhD with me, here are some ideas on various topics that I am interested in at the moment.
Traceable and incremental model-to-text transformations
One common task in model-driven software engineering is to produce text from the models: this text can be documentation, or code for the modelled system concern. Template-based languages are often used for this, with some form of co-ordination (such as the EGX and EGL languages from Epsilon). These approaches suffer from two problems, however:
- In safety-critical industries (e.g. aerospace), certification requires demonstrating that there is an unbroken chain of causality from system requirements through the system models, all the way to the implementation code. Current template-based approaches can handle simple cases where a specific model element property is directly used for the generated code, but suffer as soon as some additional processing is done (even simple string concatenation).
- When the model changes, current generators simply regenerate the entire codebase again, regardless of whether the model has only slightly changed. Some generators do detect when a given file has to be regenerated, but even then they have to regenerate the whole file. A more fine-grained level of incrementality would be desirable. This incrementality could also be used to not only generate new code, but also detect when a given set of files should be deleted, or renamed (as they may contain protected regions).
One approach to do this would be to construct a unified traceability graph, linking the model elements being accessed with the appropriate parts of the template orchestration rules and code generation templates, and the generated code.
The PhD would investigate the design of this data structure and the algorithms needed to maintain it and use it for traceable and incremental code generation.
Here is an example of what it could look like for a simple Java code generator, which turns a small model into a Product class. The graph captures the full provenance of the code, all the way from the reason why the file was generated (for renaming/deletion), to the reasons why the setPrice method was generated.

This line could also consider other uses for the captured traceability graph, e.g. enabling the propagation of information from the generated artifact (e.g. exception stack traces or compilation errors) back to the model elements that motivated their generation. This could help explain to users why their generated code did not compile when they have incorrect models. Another potential use for the traceability information is for obtaining test metrics, e.g. seeing if the test suite for our code generator is considering every important situation in the templates, and every important concept in the metamodels.
Organisation-wide model indexing and querying
Eclipse Hawk is a solution for automatically indexing models into graph databases, for easier and faster querying. Hawk can index models with millions of model elements, and it can index and query the full history of a model (which can be useful for analysing the training of a reinforcement learning agent). Hawk supports a variety of usage scenarios, including an efficient API for remote model querying via Apache Thrift:
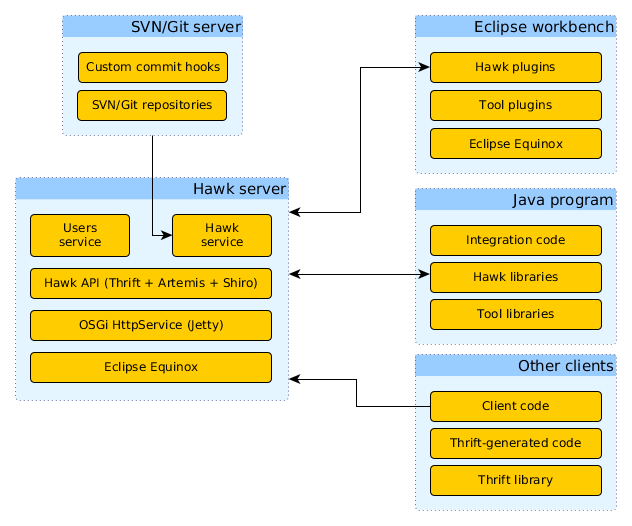
One important limitation in Hawk is that it is currently still a single-node solution, with the expected risks in terms of availability and scalability, and an inability to respond to queries while updating its index. In order to scale up to indexing all the models of an entire organisation, it would be necessary to investigate approaches that allow a Hawk index to be scaled across multiple machines, improving its availability and scalability. This will require combining state-of-the-art database technologies that can scale horizontally on their own with new distributed model indexing algorithm that take horizontal distribution into account, considering results from the distributed systems literature. It will also most likely involve the use of container orchestration platforms, such as Kubernetes.
Beyond horizontal scaling of Hawk indexes, an organisation-wide index may also require investigating more broadly accessible ways to interactively construct queries, beyond writing EOL queries. One interesting approach would be to use Large Language Models (LLMs) to automatically transform natural language queries into EOL queries, which could be then executed by Hawk. The use of LLMs would require dealing with the fact that EOL is not a mainstream programming language (and especially not the dialect used by Hawk), so publicly available LLMs will most likely not have been trained on it. This may require using alternative approaches such as restricting the output grammar of the LLM, applying few-shot learning, or applying fine-tuning to a previously existing LLM.
Another challenge is to present the results from Hawk queries and allow users to interact with them. Currently, Hawk only presents the results as a plain text string, but the underlying data structure is a graph. One possible research line would be to adapt ideas from the graph visualisation community for interactive exploration of the query results from a query made to Hawk.