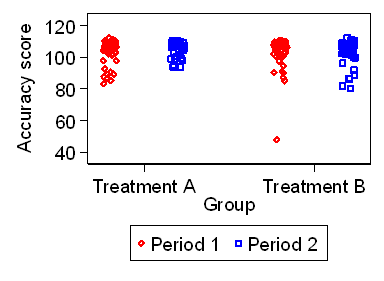
Figure 1. The accuracy test for the two periods and two treatments
The ceiling effect is apparent, and the distribution of the scores
has a distribution which is negatively skew.
It also appears that scores in Period 2 may be slightly greater
than accuracy scores in Period 1.
We can do a simple test of the treatment effect, by estimating the mean difference,
A minus B.
I have used Stata for my analyses:
The estimated treatment effect = 1.0 (95% CI –1.0 to 3.0, P=0.3).
However, we should ask whether the assumptions of this analysis are met by the data.
The mean and standard deviation of the differences should be constant
throughout the range, because we estimate them as single numbers.
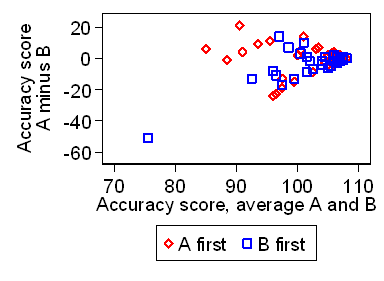
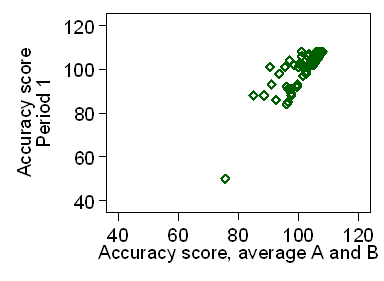
We can check this by a plot of the difference against average of the two scores,
as in Figure 2.
Figure 2. Difference in accuracy scores against average of the two scores
Clearly the standard deviation depends strongly on the accuracy.
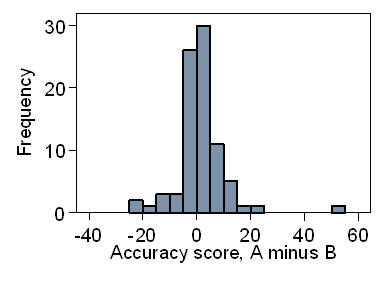
The differences should follow an approximately Normal distribution and the
histogram (Figure 3) suggests that the tails are much too long.
Figure 3. Distribution of differences in accuracy scores
Hence we should try either a transformation or nonparametric test.
I think that these data would be rather difficult to transform, because of the ceiling
giving many zero differences at the top of the range.
As the distribution of the differences is approximately symmetrical,
we could use the Wilcoxon matched-pairs (signed rank) test.
The Stata output is:
We have P = 0.3, as before.
The conclusion must be that there is no evidence for a treatment effect.
In this simple analysis, any difference between periods goes into the error.
They increase the standard deviation of treatment differences.
A better way to analyse such data is to adjust for period effects.
We can do this in two ways.
First we show a step by step method using t tests (Armitage and Hills, 1982),
then an all-in-one method using analysis of variance.
To see how the analysis works, we will use the following notation:
First we ask whether there is evidence for a period effect, i.e. are scores
in the first period the same as in the second?
For example, in this study there might be a learning effect, with accuracy
increasing with repetition of the test.
If there is no period effect, we expect the differences between the treatment
to be the same in the two periods.
The period effect, first period minus second period, will be estimated by
(A1 – A2 + B1 – B2)/2.
We can rearrange this as
(A1 – B2 – A2 + B1)/2
= (A1 – B2)/2 – (A2 – B1)/2
(A1 – B2) is the mean treatment difference for the group with A first,
(A2 – B1) is the mean treatment difference for the group with A first.
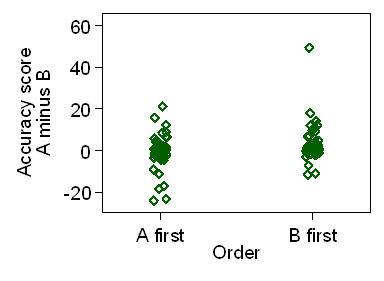
We can test the null hypothesis that the difference between these two mean differences is zero. We compare difference A minus B between orders.
Figure 4 shows a scatter plot of the difference
in accuracy score between treatments against treatment order.
Figure 4. Difference in accuracy score between treatments for the two treatment orders
We can compare the mean difference, A minus B, between the two orders
using a two sample t test:
There is weak evidence of a period effect, P=0.05.
If A is first, mean A minus B is negative, meaning the second score (B) is higher,
if B is first, mean A minus B is positive, meaning the second score (A) is higher.
The distribution in Figure 4 looks quite good for the t test,
but we can compare the non-parametric analysis.
This uses the Mann Whitney U test or two sample rank sum test:
Again we have weak evidence of a period effect, P=0.05.
The two analyses produce very similar results. So there appears to be
some evidence for a learning effect in the accuracy score.
We can allow for a possible period effect by looking at the treatment difference
for period 1, A1 – B1 and the treatment difference for period 2,
A2 – B2, and averaging them to give
(A1 – B1)/2 + (A2 – B2)/2. We can rearrange this:
(A1 – B1)/2 + (A2 – B2)/2 =
(A1 – B2)/2 – (B1 – A2)/2
Hence to estimate and test the treatment effect, we use the difference
between the average difference between period 1, A1 – B2,
and period 2, B1 – A2, for the two orders.
This is called the CROS analysis.
We get:
The estimate of the effect is half the observed difference:
2.163925/2 = 1.1 (95% CI –0.9 to 3.0, P=0.3).
There is no evidence for a treatment effect.
The non-parametric equivalent is a Mann Whitney U test of the difference,
period 1 minus period 2, between the two orders:
Again there is no evidence for a treatment effect, P=0.3.
The two analyses give very similar results.
We can do the same analysis by analysis of variance, with accuracy score as the
outcome variable and subject, treatment, and period as factors:
If we compare the results of the CROS analysis with the simple paired t test,
we have treatment estimate 1.1 (95% CI –0.9 to 3.0, P=0.3) by CROS
and estimated treatment effect = 1.0 (95% CI –1.0 to 3.0, P=0.3) by paired t test.
In fact the P value for the CROS test is fractionally smaller, 0.28 compared to 0.31,
and the confidence interval very slightly narrower, so ignoring the period effect
has little impact on the results in this example.
In general though, it is better to take the period effect into account
and do the CROS analysis.
The period effect might be bigger than here and there is nothing to lose.
Back to top.
We often want to ask whether the effects of B are the same if it follows A
as they are if B comes first.
In the mental fatigue trial, there could be an interaction because of the
ceiling effect and practice improving accuracy.
Treatment A could raise scores to the ceiling and all participants could get
near the ceiling in the second period, due to practice.
This would result in no treatment difference if A came first,
but a difference if B came first.
We ask whether the treatment difference is the same whatever order of treatments is given.
In other words, is there an interaction between period and treatment?
Is there an order effect?
If there is no interaction, the participants average response should be the
same whichever order treatments were given.
We ask: is A1 + B2 = A2 + B1?
Note that this is the same as comparing the treatment difference in period 1
with the treatment difference in period 2:
is A1 – B1 = A2 – B2?
To test for a period × treatment interaction, we can compare the sum
or the average of the scores on the two treatments between orders.
The participants average response should be the same in whichever order treatments
are given.
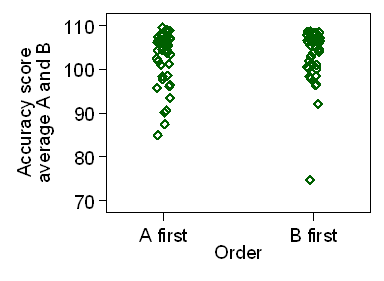
Figure 5 shows the average score for treatments A and B
plotted against the order in which treatments were given.
Figure 5. Average score for treatments A and B by order in which treatments were given
We can compare average between orders using a two sample t test:
There is no evidence of an interaction, P=0.6.
However, the distributions shown in Figure 5 are negatively skew,
not Normal and the assumptions for the t test are not well met.
We can do a Mann Whitney U test instead:
Again we have P = 0.6 and no evidence of any interaction between treatment
and order in this trial.
The power of the test of interaction is low and alpha = 0.10 is often recommended
as a decision point, rather that 0.05.
As we shall see below, the real question is whether we should test at all
and what we should do if we find anything.
Back to top.
In the mental fatigue trial, there could be an interaction because of the ceiling
effect and practice.
Another possibility in cross-over trials is a carry-over effect,
where the first treatment continues to have an effect in the second period.
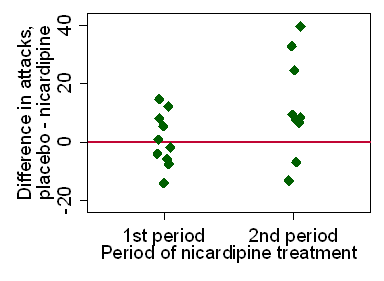
This example, a trial of Nicardipine against placebo in patients with
Raynauds phenomenon (Kahan et al., 1987) was given by Altman (1991).
Patients with Raynauds phenomenon were given either the drug
Nicardipine or a placebo, each for a two week period, in random order.
They were asked to record the number of attacks of Raynauds phenomenon
which they experienced.
Table 3 shows the results.
(Observations have been jittered slightly so that they can be seen.)
. ttest diffamb=0
One-sample t test
------------------------------------------------------------------------------
Variable | Obs Mean Std. Err. Std. Dev. [95% Conf. Interval]
---------+--------------------------------------------------------------------
diffamb | 84 1.035714 1.0045 9.206397 -.9621963 3.033625
------------------------------------------------------------------------------
Degrees of freedom: 83
Ho: mean(diffamb) = 0
Ha: mean < 0 Ha: mean != 0 Ha: mean > 0
t = 1.0311 t = 1.0311 t = 1.0311
P < t = 0.8472 P > |t| = 0.3055 P > t = 0.1528
. signrank diffamb=0
Wilcoxon signed-rank test
sign | obs sum ranks expected
-------------+---------------------------------
positive | 36 1991.5 1739.5
negative | 35 1487.5 1739.5
zero | 13 91 91
-------------+---------------------------------
all | 84 3570 3570
unadjusted variance 50277.50
adjustment for ties -180.00
adjustment for zeros -204.75
----------
adjusted variance 49892.75
Ho: diffamb = 0
z = 1.128
Prob > |z| = 0.2592
. ttest diffamb, by(order)
Two-sample t test with equal variances
------------------------------------------------------------------------------
Group | Obs Mean Std. Err. Std. Dev. [95% Conf. Interval]
---------+--------------------------------------------------------------------
A first | 43 -.8604651 1.295952 8.498127 -3.475803 1.754872
B first | 41 3.02439 1.498978 9.598145 -.0051582 6.053939
---------+--------------------------------------------------------------------
combined | 84 1.035714 1.0045 9.206397 -.9621963 3.033625
---------+--------------------------------------------------------------------
diff | -3.884855 1.975746 -7.815243 .0455321
------------------------------------------------------------------------------
Degrees of freedom: 82
Ho: mean(A first) - mean(B first) = diff = 0
Ha: diff < 0 Ha: diff != 0 Ha: diff > 0
t = -1.9663 t = -1.9663 t = -1.9663
P < t = 0.0263 P > |t| = 0.0527 P > t = 0.9737
. ranksum diffamb, by(order)
Two-sample Wilcoxon rank-sum (Mann-Whitney) test
order | obs rank sum expected
-------------+---------------------------------
A first | 43 1610 1827.5
B first | 41 1960 1742.5
-------------+---------------------------------
combined | 84 3570 3570
unadjusted variance 12487.92
adjustment for ties -151.09
----------
adjusted variance 12336.83
Ho: diffamb(order==A first) = diffamb(order==B first)
z = -1.958
Prob > |z| = 0.0502
. ttest diff1m2, by(order)
Two-sample t test with equal variances
------------------------------------------------------------------------------
Group | Obs Mean Std. Err. Std. Dev. [95% Conf. Interval]
---------+--------------------------------------------------------------------
A first | 43 -.8604651 1.295952 8.498127 -3.475803 1.754872
B first | 41 -3.02439 1.498978 9.598145 -6.053939 .0051582
---------+--------------------------------------------------------------------
combined | 84 -1.916667 .9887793 9.062312 -3.883309 .0499756
---------+--------------------------------------------------------------------
diff | 2.163925 1.975746 -1.766462 6.094313
------------------------------------------------------------------------------
diff = mean(A first) - mean(B first) t = 1.0952
Ho: diff = 0 degrees of freedom = 82
Ha: diff < 0 Ha: diff != 0 Ha: diff > 0
Pr(T < t) = 0.8617 Pr(|T| > |t|) = 0.2766 Pr(T > t) = 0.1383
. ranksum diff1m2, by(order)
Two-sample Wilcoxon rank-sum (Mann-Whitney) test
order | obs rank sum expected
-------------+---------------------------------
A first | 43 1949 1827.5
B first | 41 1621 1742.5
-------------+---------------------------------
combined | 84 3570 3570
unadjusted variance 12487.92
adjustment for ties -100.77
----------
adjusted variance 12387.15
Ho: diff1m2(order==A first) = diff1m2(order==B first)
z = 1.092
Prob > |z| = 0.2750
. anova score sub treat period
Number of obs = 170 R-squared = 0.6490
Root MSE = 6.40033 Adj R-squared = 0.2765
Source | Partial SS df MS F Prob > F
-----------+----------------------------------------------------
Model | 6210.08374 87 71.3802729 1.74 0.0059
|
sub | 5990.61699 85 70.4778469 1.72 0.0071
treat | 49.1391331 1 49.1391331 1.20 0.2766
period | 158.377228 1 158.377228 3.87 0.0527
|
Residual | 3359.0692 82 40.9642585
-----------+----------------------------------------------------
Total | 9569.15294 169 56.6222068
Interaction between period and treatment
. ttest av1and2, by(order)
Two-sample t test with equal variances
------------------------------------------------------------------------------
Group | Obs Mean Std. Err. Std. Dev. [95% Conf. Interval]
---------+--------------------------------------------------------------------
A first | 43 102.593 .9138191 5.992312 100.7489 104.4372
B first | 41 103.2439 .9346191 5.984482 101.355 105.1328
---------+--------------------------------------------------------------------
combined | 84 102.9107 .6504313 5.961301 101.617 104.2044
---------+--------------------------------------------------------------------
diff | -.6508792 1.307167 -3.251251 1.949493
------------------------------------------------------------------------------
Degrees of freedom: 82
Ho: mean(A first) - mean(B first) = diff = 0
Ha: diff < 0 Ha: diff != 0 Ha: diff > 0
t = -0.4979 t = -0.4979 t = -0.4979
P < t = 0.3099 P > |t| = 0.6199 P > t = 0.6901
. ranksum av1and2, by(order)
Two-sample Wilcoxon rank-sum (Mann-Whitney) test
order | obs rank sum expected
-------------+---------------------------------
A first | 43 1766 1827.5
B first | 41 1804 1742.5
-------------+---------------------------------
combined | 84 3570 3570
unadjusted variance 12487.92
adjustment for ties -67.77
----------
adjusted variance 12420.15
Ho: av1and2(order==A first) = av1and2(order==B first)
z = -0.552
Prob > |z| = 0.5811
Carry over effects