 |
 |
|
|
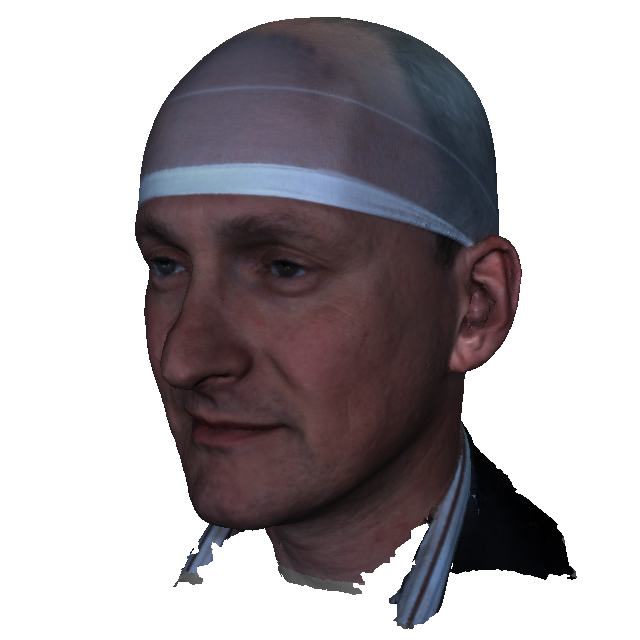
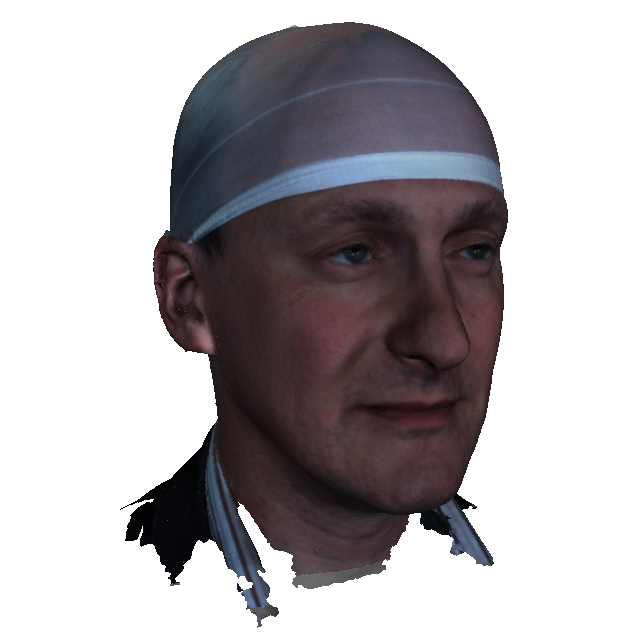
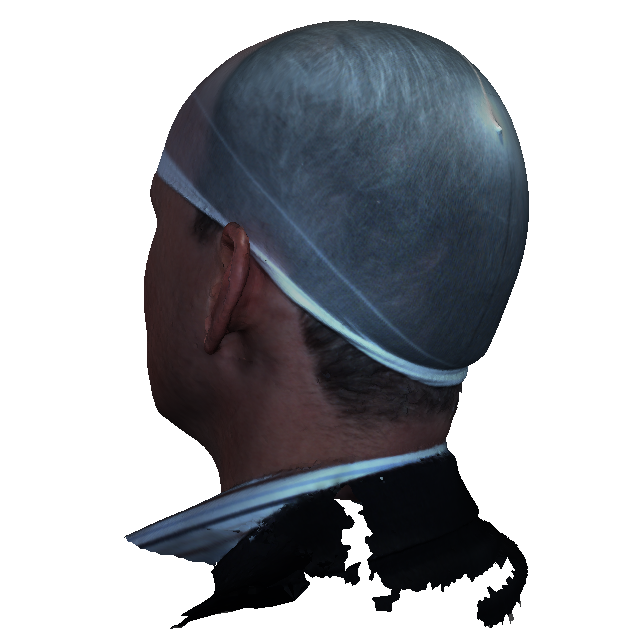
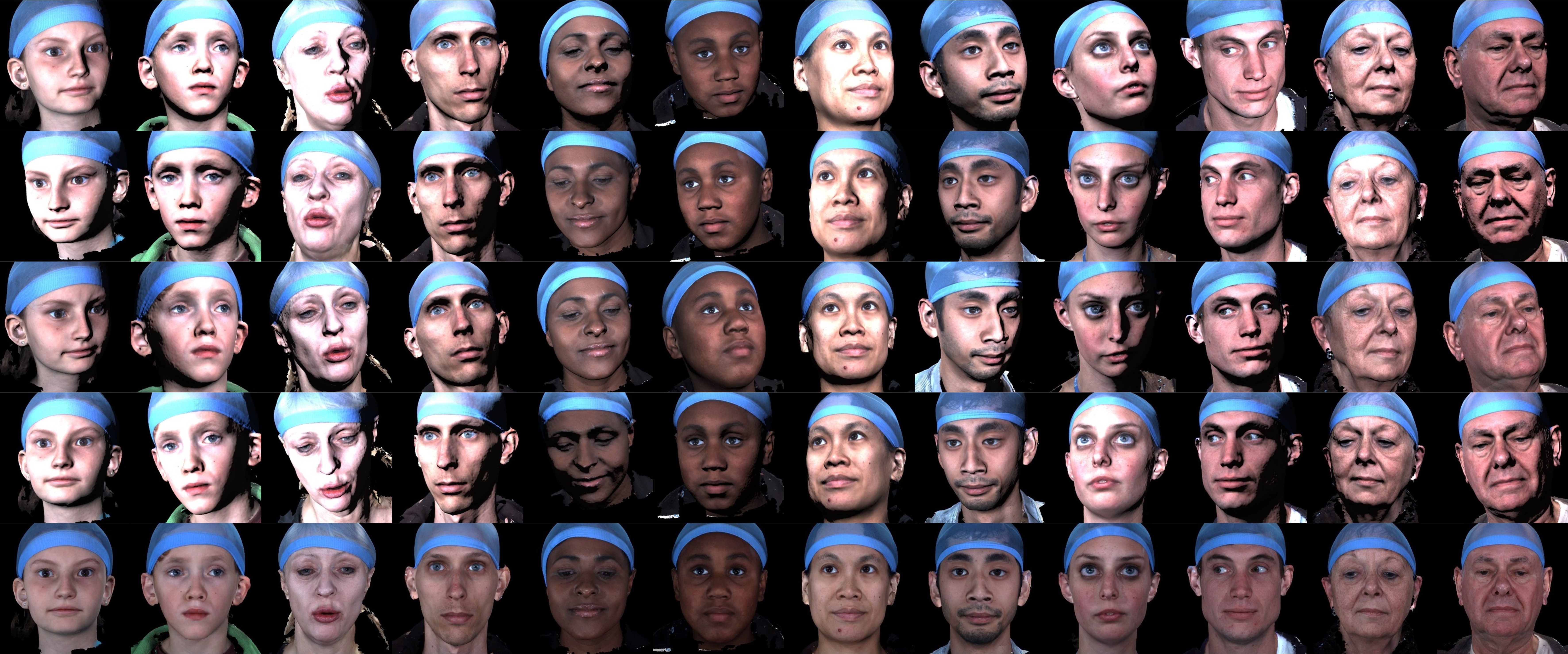
The Headspace dataset is a set of 3D images of the human head, consisting of 1519 subjects wearing tight fitting latex caps to reduce the effect of hairstyles. The dataset is free for University-based non-commercial research. It can only be requested by academics that are verifiable university employees using the same user agreement form as for the LYHM model. Students must get their academic supervisors to request the data. An email linked to a Google account must be supplied to allow the distribution via Google drive. The download file is a compressed tarball (.tar.gz), with file size 38GB. The indices of the 1212 subjects that we used for the LYHM 3D Morphable Model (3DMM) are provided with the dataset.
There are various auxiliary components of the dataset available in request, which includes:
The data collection was planned and implemented by the Alder Hey Craniofacial Unit, under the direction of Christian Duncan, lead Craniofacial clinician. The process employed 3dMD's static 3dMDhead scanning system to capture 1519 3D images of the human head (filtered to 1212 images for our global 3D Morphable Model build). The initial collection was supported by QIDIS and the work in 2017-18 was supported by Google Faculty Awards in the 'Headspace Online' project, with sponsor Forrester Cole (Google, Cambridge, MA).
The data is in OBJ format with BMP textures and is available online for download.
Directories are per subject and named with subject indices from 00001 to 01519. Within each directory are the following files, where root is 12 digit 3D image identifier.
The dataset is supplied with subject-based and capture-based metadata in the file 'subject.txt'. The subject information includes: gender, declared ethnic group, age, eye color, hair color, beard descriptor (none, low, medium, high), moustache descriptor (none, low, medium, high), and a spectacles flag. The capture information contains a quality descriptor (free text, such as `data spike right upper lip'), a hair bulge flag (hair bulge under latex cap distorting the apparent cranial shape), a cap artefact flag (cap has a ridge at its apex due to poor fitting), a cranial hole flag (a missing part in the data scan at the cranium) and an under chin hole flag (missing part under chin).
Matlab code is included for viewing the dataset, or other utilities can be used, such as MeshLab.
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
A new variant of non-rigid iterative closest points (non-rigid ICP) for fully-dense, fully automatic, fast 3D shape morphing (3D-to-3D registration) has been designed by the VGL group at York and evaluated on the Headspace dataset. This work, termed Laplacian ICP [L-ICP paper, PDF] [BibTeX] was published at IEEE Conf. on Automatic Face and Gesture Recognition 2023, 7-8th Jan 2023. Effectively it uses the concept of Laplacian mesh editing (Sorkine et al 2004, SGP'04) embodied in a fully-automatic, fully-dense ICP framework, to give a fast algorithm (sparse linear solve per iteration), where the shape morphing process doesn't require training. The work was evaluated by augmenting the Headspace dataset with manual contour annotations and designing two new metrics associated with the consistency and homogeneity on annotation transfer from the data 3D scan to the deformed 3D template.
The image below shows two radically different subjects in terms of head size/shape in the Headspace dataset. The left two columns show manual annotations on raw PNG images. In the third column, the two-view annotations are amalgamated and projected to their 3D target scans. In the fourth column, we show the morphed templates with annotations transferred using nearest neighbours after the morphing process. Finally, in the right column, the annotations are swapped across the two subjects.
We repeat the L-ICP template morphing process for 675 Heaspace subjects and, if the 3D shape morphing of the template is consistent, we expect the same annotations to transfer to the same vertices on the template - or at least to those that are within a small neighbourhood. This leads to the quantitative metrics for annotation transfer density and annotation transfer homogeneity (see paper for details). Annotation transfer density can also be viewed qualitatively as the sharpness of the 675 sets of overlaid annotations onto the unwarped template, as shown in the figure below.
Wojciech Zielonka, Timo Bolkart and Justus Thies have kindly provided a set of FLAME model registrations and FLAME model parameters for the Headspace dataset via the MICA project. These registrations are shown in the figure below. Please indicate if you want these FLAME registrations and parameters to be included in your dataset distribution using the download selection table on the agreement form. The same restrictions apply as for the raw data, in that these meshes are for non-commercial, University-based research use only. If they are employed in your research, then you should cite the following MICA project publication,
also citing the following Dai et al 2020 IJCV paper for primary Headspace data:
 |
The REALY project presents a region-aware evaluation with publicly-available code for 3D face reconstruction. It employs 100 scans from the Headspace dataset and is published at ECCV 2022.
Please indicate if you want to use the REALY benchmark for evaluation on the user agreement form. The same restrictions apply as for the raw data, in that these meshes are for non-commercial, University-based research use only. If they are employed in your research, then you should cite the following REALY project publication:
also citing the following Dai et al 2020 IJCV paper for primary Headspace data:
After unzipping the REALY download file, you will find three folders, as follows:
 |
 |
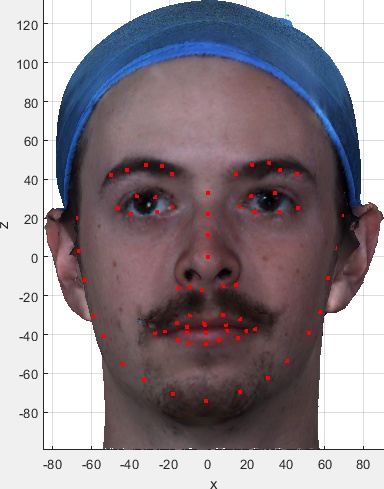
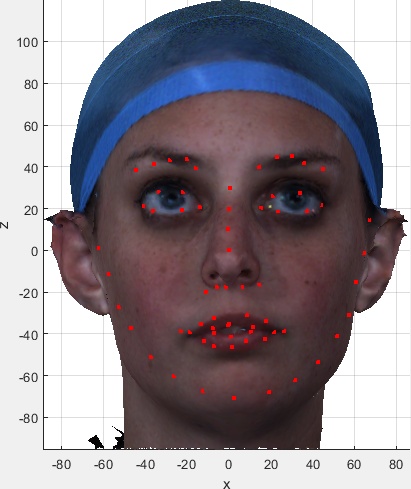
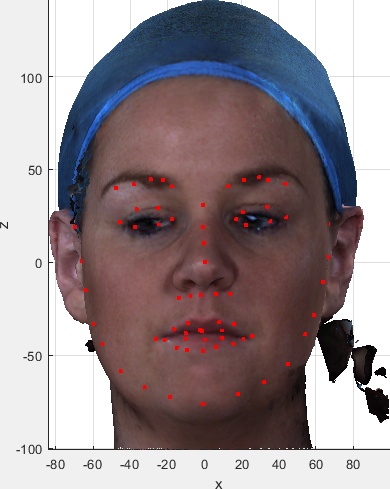
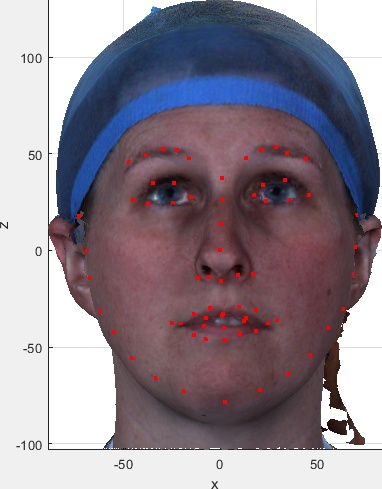
These are useful for visual indexing of the dataset and visually checking the correctness of the meta data and automatic landmark extraction. They were kindly provided by Zach Fishman working with Prof Cari Whyne at the Orthopaedic Biomechanics Lab, Sunnybrook Research Institute and University of Toronto. If you want these images and the spreadsheet summarising the subject/image meta data, please indicate this in the download selection table on the user agreement form.
 |
 |
 |
 |
 |
 |
 |
 |
 |
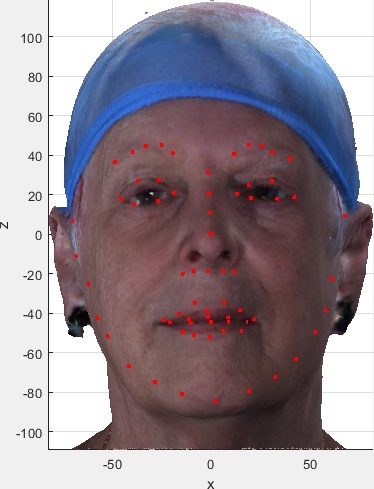 |
Early releases of the dataset (version 1 - pre August 2018) have 1518 subject ID directories, whilst later releases (v02) have 1519. This is because one OBJ file was put in the wrong subject ID directory on collection, and hence associated with the wrong subject meta-data (age, gender, etc). This is an 8-year old girl (meta data here), who was in the directory of a 26 year old male (meta data here). Her scan is moved from subject ID 01400 to 01519 in the v02 release, and the correct meta data of the 26 year-old male is now associated with subject 01400.
This is only important if you are using subject 1400 and the meta data. In this case you can clearly use ensure the correct meta data is being used by visual inspection.
Please cite the 2020 IJCV paper, first in the list below, if you are using our models and/or dataset.
Our arXiv paper details our early 100-subject prototype models that were developed in 2015, and can be found here.
BACK to Nick Pears' Research Projects page.