 d
d
A talk given by Martin Bland at `The Contribution of Statistics to Public Health', a meeting in honour of Tony Swan, 11th October 2001, at the Public Health Laboratory Service Disease Surveillance Centre, Colindale.
Cluster designs are those where research subjects are not sampled independently, but in a group. They can be experimental, such as a trial where all the patients in a general practice are allocated to the same intervention, the general practice forming a cluster. They can be observational, such as a study where several towns are selected and then people are chosen for interview within those towns, the people in the town forming a cluster. In either case, members of a cluster will be more like one another than they are like members of other clusters. We need to take this into account in the analysis, and preferably the design, of the study. Methods which ignore clustering may mislead, because they assume that all subjects are independent observations. This is not the case in a cluster design, because observations within the same cluster are correlated. This may lead to confidence intervals which are too narrow and P values which are too small.
I have made little theoretical contribution to the design or analysis of
cluster designs. However, it is in area in which I have always been interested
from a practical point of view, particularly in terms of encouraging others to
take clustering into account. What I am going to describe is a personal
Odyssey, which I think reflects the increasing importance which the medical
research community attaches to the appropriate treatment of clustering.
The Derbyshire Smoking Study
I joined St. Thomas's Hospital Medical School in 1972. Much of my work there involved the analysis and design of studies of respiratory disease and cigarette smoking among schoolchildren. The largest of these was the Derbyshire smoking study, on which Tony and I worked at different times and which provided both of us with the material for our PhD theses. Like all these studies, this was based in schools. All the children in the target age group within the school would be invited to take part in the study.
In the Derbyshire Smoking Study, schools were allocated into several groups. There was a main study group, where children were to be studied each year, a Hawthorne effect group, where children were to be studied in the last year of the study only, and an intervention group to be used in a subsequent trial. Schools were allocated to these groups randomly. There were even clusters of schools, where several middle schools fed into the same senior school. Thus this study was certainly clustered by school.
The analysis of the main study group which I carried out ignored this clustering. Last year Janet Peacock and I wrote our book Statistical Questions in Evidence-based Medicine, which contained a lot of questions about mistakes in design and analysis. We thought it only fair to those we criticised that we should find a few published mistakes of our own to include. When I was looking for my published mistakes, I had trouble finding any. This was not because I don't make them, but because of course I don't know that they are mistakes. I would only find them if others pointed them out. One which I did know that I had made was ignoring clustering in the Derbyshire Smoking Study, so into the book it went.
I asked myself why I had made this particular mistake? I could say that the
reason was the availability of software & hardware for dealing with
relationships within fifty clusters. I could even admit that the reason was
ignorance of the statistical procedures needed. But although these might both
have been relevant, the real reason was that it just did not occur to me. It
doesn't occur to very many researchers.
A two-cluster study
However, I was certainly aware of these issues at the time. I remember vividly that at St. Thomas's one of my fellow statisticians, who shall remain nameless to protect the innocent, proposed a study which compared two geographical regions, one with and one without the risk factor. We had an excellent system of exposing all proposed studies to ruthless departmental scrutiny. I went to the meeting resolved to be diplomatic about the problems of clustering in this design, but diplomacy failed me and I ended up making a little speech referring to pigs in pens. I am sorry to say that this reduced my colleague to tears and a dark night of the soul in which she questioned her right to call herself a statistician. However, she recovered, relabelled herself as an epidemiologist, redesigned the study with more clusters, and carried it to a successful conclusion. The paper contained the following:
'The units for analysis are the London boroughs and some adjacent urban districts and municipal boroughs . . .'
A quick search on the Science Citation Index revealed 53 publications in her
name, so recovery was complete.
An Introduction to Medical Statistics, 1st edition
I left St. Thomas's and joined St. George's Hospital Medical School, where I
have been ever since. There I wrote my first book, An
Introduction to Medical Statistics, published in 1987. I included a brief
discussion of cluster randomisation, under the heading 'Experimental units'. I
don't think that I had come across the term 'cluster' then, but used terms such
as 'unit of allocation' or 'unit of analysis'. (The earliest reference I can
find to cluster randomisation is a paper by Alan Donner in 1982, and only one
other before 1989.)
GP education trial
Then my new department proposed a trial of the education of General Practioners (GPs, primary care physicians) to improve treatment of asthma. The idea was to educate GPs in small groups, or not, and to evaluate this education by giving repeated questionnaires to their asthmatic patients. I was asked for my views on the sample size calculations, which ignored the clustering and the GPs, and treated the design as a comparison of two groups of patients. I was appalled, and set about the education of my senior colleagues. I can't recall how I did it now, but I produced a sample size calculation based primarily on the number of GPs, not patients. The trial was funded and a research fellow, a GP, appointed. The trial began. The cluster nature of the study was self-evident to me, because it was a trial, even though I was not aware of term cluster randomisation. It was not self-evident to the research fellow, with whom I had seemingly endless discussions. Every two or three weeks, he would come to my office and say 'Martin, can you just explain it to me again?'. The study appeared including the following description of the analysis:
'For each general practitioner a score was calculated for each questionnaire
item. Analysis of variance was then carried out for each questionnaire item to
compare the three groups . . . '
MRC project board
About 10 years ago I was asked to join the Medical Research Council project
board for public health and health services research. At an early meeting, we
considered a proposal to compare four different interventions in hospital
wards, using four wards, one ward per treatment. I explained the problems in
this design to the Board. The proposal was turned down. It was later
resubmitted with several wards per treatment, and if I remember correctly then
received a high rating. This process was repeated many times, as funding was
sought for proposals which ignored the clustering in the design. The Board
became quite used to it, and when such proposals came along would quip 'Go on,
Martin, we know what you are going to say.' Then these proposals stopped.
Cluster randomised trials came instead with proposals for multi-level modelling
and with sample sizes based on intra-class correlations. I discovered that the
MRC secretariat were warning applicants with cluster-randomised trials that
they would not be funded if the clustering were not taken into account, and
advising them to seek statistical help.
Primary/secondary care interface
I then joined the commissioning body for the Department of Health initiative on
the primary/secondary care interface. This produced many proposals for
cluster-randomised designs, which often showed awareness of the need to take
the clustering into account. Many of these proposed multilevel modelling. I
was sceptical about the ability of all these applicants actually to do
multilevel modelling, but pleased that the message had got through.
A refereeing case study
An interesting case was a paper sent to me in 1997 by the BMJ. This gave me great pleasure, as it managed to include several of my favourite statistical errors.
It was a study of the impact of a specialist outreach team on the quality of nursing and residential home care. The intervention was carried out at the residential home level. Eligible homes were put into matched pairs and one of each pair randomised to intervention. Thus the randomisation was clustered. This intervention was applied to the care staff, not to the patients. The residents in the home were used to monitor the effect of the intervention on the staff.
The clustering was totally ignored in the analysis. What they did was to use the patient as the unit of analysis, then carry out a Mann-Whitney test of the scores between the two groups at baseline. This was not significant, as we might expect, the homes being randomised, although ignoring clustering may decrease the P value for a chance finding. They then did the same at follow-up, completely ignoring the baseline measurements. Of course, the fact that the difference is not significant at baseline does not mean we should ignore baseline variables. It is likely that follow-up score is related to the base-line score at the patient level and much residual variability could be removed by allowing for it. As neither of these Mann-Whitney tests was significant, the authors then did a Wilcoxon matched pairs test for each group separately and found that one was significant and the other not. Not significant means only that we have failed to detect a difference, not that there isn't one, so the comparison of these two paired tests was meaningless.
I suggested two possible approaches to the analysis. We could use a summary statistic for the home, e.g. the mean change in score or mean cost. These could then be compared using a t method. As the homes were randomised within pairs, I suggested that the paired t method would be appropriate. (This may not be right, as the matching variables may not be informative and the loss of degrees of freedom may be a problem.) The results should be given as a difference in mean change, with a confidence interval as recommended in the BMJ's guide-lines, rather than as a P value. (I seem to say this often.) The alternative approach would be to fit a multi-level model, with homes as one level of variability, subjects another, and variation within subjects a third. This, I thought, was strictly a job for a professional statistician. I thought that a simple summary measure analysis would suffice.
The paper was rejected. Time passed and I became curious about the ultimate fate of this paper. I searched on the author's name and found the study reported in the Lancet! There was an extra author, a well-known medical statistician. Here is an extract:
'The unit of randomisation in the study was the residential home and not the resident. Thus, all data were analysed by use of general estimated equation models to adjust for clustering effects within homes. . . . Clinical data are presented as means with 95% CIs calculated with Huber variance estimates.'
I looked for the acknowledgement to an unknown referee, in vain.
Publications on cluster designs
About this time began a rash of how-to-do-it papers, statistics notes in the BMJ, articles in GP journals, special editions of Statistical Methods in Medical Research and Statistics in Medicine, and papers reporting intraclass correlation coefficients to help others to design clustered studies.
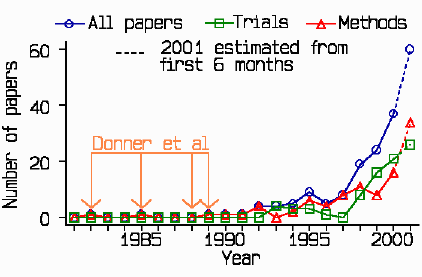
Below are the results of a Web of Science search on: randomi* in clusters OR cluster randomi*:
This is not a thorough search and will have missed many studies, but it gives an idea of the increase in activity. The data for 2001 have been extrapolated from half the year. This includes a special issue of Statistics in Medicine on cluster randomisation, so the methods papers may not be quite so many as my estimate suggests.
The search ignores papers using clusters in observational studies. These would be harder to identify. I suspect there are few of them.
All the papers up to 1990 are due to Alan Donner and his colleagues, who must
have introduced the term 'cluster' in this context.
Donner comes to Britain
In 1998, Allan Donner, author of that 1982 paper and of many others on the
topic, came to a meeting on cluster-randomised trials in Oxford. He was
delighted to be in same room with so many people who cared about this topic.
He had thought nobody apart from himself was interested in the subject, but in
the UK it was clearly an idea for which the time had come.
Bupa Foundation meeting
Finally, in 1999 I attended a Bupa Foundation meeting on clinical guidelines,
where I was asked to give a talk on sample size for trials of guidelines.
Guidelines trials tend to be clustered; guidelines are given to some providers
(e.g. GPs) and not to others, then their subsequent patients are used to assess
the impact. My talk on sample size went into clustering. One of the attendees
at this talk was heard to wail afterwards 'My life's work is in ruins!'. Well,
it saved the rest of her life's work from being a ruin too, so I count it a job
well done.
Conclusions
When I began as a medical statistician in 1972, the importance of clustering in study design and analysis was appreciated only by a few statisticians. In the 1990s this knowledge spread into the medical research community and in turn generated more interest among statisticians and a desire to educate researchers.
Although there has been a great increase in awareness of the importance of cluster randomisation, I suspect that there is still a long way to go on dealing with clustering in observational studies. The issues here are more subtle. We are usually, but not always, dealing with relationships at the indivdual level, within the cluster.
There is more to do, more papers to write, more talks to give, more lives to
rescue from ignorance and ruin. Join me in this noble endeavour!
References
Banks MH, Bewley BR, Bland JM, Dean JR, Pollard VM. A long term study of smoking by secondary schoolchildren. Archives of Disease in Childhood 1978; 53: 12-19.
Bland M and Peacock J. Statistical Questions in Evidence-based Medicine Oxford: University Press, 2000.
Bland M. An Introduction to Medical Statistics Oxford: University Press, 1987.
Donner, A. An empirical-study of cluster randomization. International Journal of Epidemiology 1982; 11: 283-286.
Donner, A. A regression approach to the analysis of data arising from cluster randomization. International Journal of Epidemiology 1985; 14: 322-326.
Donner, A, and Hauck, W. Estimation of a common odds ratio in paired-cluster randomization designs. Statistics in Medicine 1989; 8: 599-607
Donner A, Brown KS, Brasher P. A methodological review of non-therapeutic intervention trials employing cluster randomization, 1979-1989. International Journal of Epidemiology 1990; 19: 795-800.
Bland JM. Sample size in guidelines trials. Family Practice 2000; 17: S17-S20. Full text of presentation.
Back to clustered study designs menu.
Back to some papers and talks menu.
Back to Martin Bland's Home Page.
This page maintained by Martin Bland.
Last updated: April 5, 2004.