 | Background - Serial Order Model - Representing Spoken Words Model - Syllabic Phase Predictions Back to my Homepage For Potential Graduate Students |
| Background - Serial Order Model - Representing Spoken Words Model - Syllabic Phase Predictions Back to my Homepage For Potential Graduate Students |
Speech is inherently serial whether we are thinking about the ordering of sounds in a syllable, or of the words in a sentence. This serial structure is incorporated into our memories, we remember the order of the phonemes that make up a word, we remember the order of the words in a poem. How is this serial structure represented neurally?
A
|
|
B 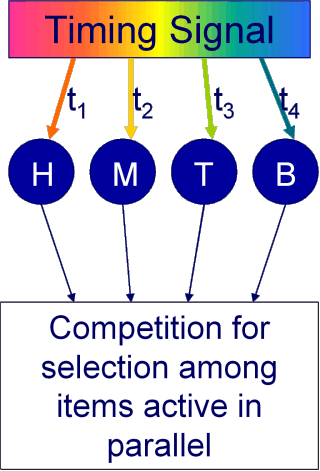
|
|
C |
One approach (Figure 1A) has been to suggest that sequences of actions are stored as chains of associations. So that in storing the sequence H,M,T,B the neural representation of H becomes associated with that of M and so on, with the result that activating H tends to activate each of the subsequent letters in turn.
Although this model is appealingly simple it has a number of problems as a model of serial order in verbal memory. Probably the most important problem is that it fails to account for a rather common type of error in which different, often adjacent, elements swap with one another.
A more successful approach to modelling serial order has been Competitive Queuing (Figure 1B) in which items to be sequenced become associated with a dynamic timing signal. The state of the timing signal changes continuously during presentation so that by a simple Hebbian rule, items perceived at different times will become associated with different states of the timing signal.
To recall a sequence of items, the timing signal is “replayed”, which has the effect of activating the items in the sequence they were originally experienced. However as nearby states of the signal are similar items are active in parallel and compete to be output.
There might be different timing signals for different tasks, and we can get some idea of the nature of the timing signal from the types of error we see in each task.
In the Competitive Queuing model, items in the list have to compete with one another for output, and because the timing signal changes gradually over time the greatest competition is between items close together in the list (Figure 1C). With a little noise in the system, the wrong item will occasionally be selected for output. This can easily result in a paired transposition as the "correct" item remains active and is very likely to be output at the next position in the sequence.
A competitive queuing model with this kind of linear timing signal can account very well for the typical errors data from classical STM tasks in which the items to be recalled are familiar digits or letters.
Another task that might have a different timing signal is nonword repetition: just repeating back a word you have never heard before (usually a nonsense word).
In this task the most common errors involve the transposition of sounds from one syllable into the same part of another nearby syllable. Sounds within a syllable are rarely, if ever, transposed. This means that a linear timing signal cannot account for the pattern of errors. Instead it suggests that the timing signal involved in encoding the sequence of phonemes within a list of syllables has a cyclical component which is synchronised with the syllable. So that, for instance, the initial sound in each syllable is associated with a very similar state of the timing signal (Figure 2A).
|
A |
|
B 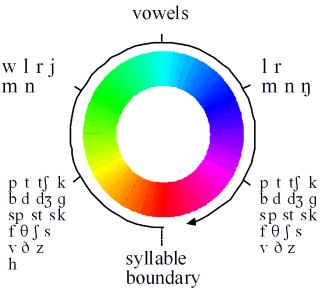
|
This kind of mechanism does not just explain errors in STM, but can also explain everyday slips-of-the-tongue which obey very similar constraints (Vousden, Brown and Harley, 2000). So it seems as if this cyclical syllable structure is incorporated into long-term memory, too.
But the case of short term memory remains particularly interesting, because in STM and when we first learn new words, the syllable’s structure must be determined as it is perceived, as we have no pre-existing representation (i.e., we need a perceptual mechanism to synchronize the timing signal to the perceived syllables). This perceptual mechanism plays an important part in determining the nature of long-term representations of speech -- but how might it work?
Initially, we proposed a phonological solution (Figure 2B).
As each phoneme is perceived, the next corresponding clockwise slot is activated.
e.g., /top hat/
At recall phonemes occupying the same slot compete to be output occasionally producing between syllable transpositions.
In fact, our simulations showed all the observed error types in approximately the observed proportions and importantly, no others.
However, this phonological template is slightly unsatisfactory as it is language specific, and it is not clear how it could be learned without some pre-existing cyclical timing signal synchronized with the syllable. In more recent work I proposed that the timing signal for phonemic sequencing is based on acoustic information, which avoids these difficulties, arriving at a more detailed neural model of the acoustic-temporal processes required for forming new serially-ordered phonological representations.
|
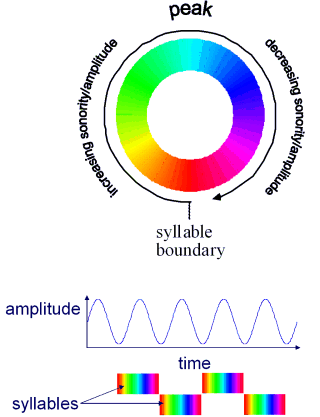
The pattern of ordering of the phonemes in a syllable reflects a consistent pattern of amplitude modulation within the syllable. Louder sounds occur near the vocalic peak, quieter sounds further away. Provided these peaks are more or less regular we can exploit signal processing methods to determine where we are in a given cycle on the basis of the envelope of the speech signal. In other words we can measure the phase of the syllable cycle from bottom-up information (Figure 3A).
Note that in this cyclical model of syllable perception, the transitions between syllables are smooth: the boundary is somewhat arbitrary. This helps to explain why subjects generally agree on the number of syllables in an utterance, but disagree about the syllabification of intervocalic consonants (e.g., the /m/ in lemon).
Here’s how the mechanism might work in the brain. (Figure 4)
|
A 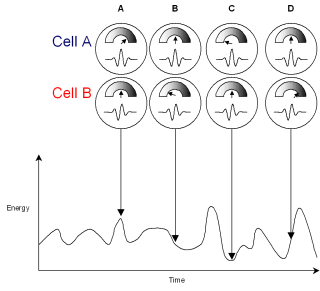
|
|
B 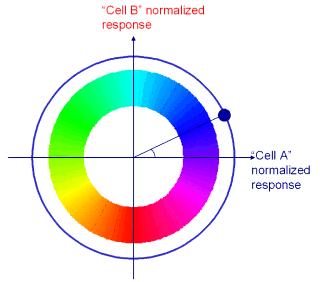
|
|
C 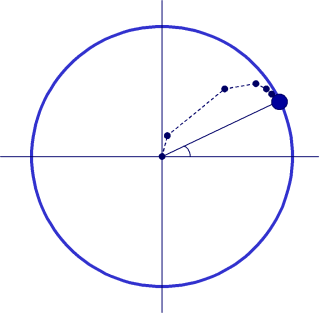
|
Cells A and B here are sensitive to amplitude modulation at a typical speech rate, say 4 syllables per second.
Cell ‘A’ is tuned to respond to the shape of a typical syllable, that is a peak in the envelope surrounded by two troughs about 250ms apart. Whenever this acoustic pattern is present in the input, the cell will respond strongly. (time A).
If the gap between the troughs is a little wider, say 300 ms the cell will still respond, but less strongly (this is useful when dealing with variable speech rates, below). However when a trough is encountered the cell’s firing is inhibited (time C). Between peaks and troughs the firing rate is between these extremes (times B and D).
Cell B is very similar but its greatest response is to the onset of a syllable.
By looking at the firing rate of both cells together we can distinguish the beginning middle and end of a syllable, and in fact the firing of the two cells varies smoothly and continuously.
In fact, for an ideal pair of cells, with a regularly varying input, the combined response of the pair traces a circular path around the origin. So the angle the output makes with the origin gives us the phase of the cycle.
The method also tracks phase accurately even when the rate varies by up to 50%.
One problem for this simple model is that real speech rates (in English) may vary by much more than this.
As noted above, the absolute firing rate of the cells depends on the degree to which the tuning of the cell’s matches the current speech rate. If we have a population of pairs of cells, each tuned to different possible speech rates, we can define a rate independent measure of phase by vector addition of each pair. This works because of the way poorly tuned cells (cells whose tuning is mismatched to the local speech rate) make less of a contribution to the phase of the sum vector. The angle the vector makes with the origin represents position with the syllable, while the length of this vector gives an indication of the confidence attached to this.
It turns out that this population vector tracks varying speech rate fairly accurately, cycles of the population vector correlate well with gold-standard syllable counts based on phonetic transcription (r=0.8) and critically vowels tend strongly to be associated with phases near zero, while consonants occur at phases near to +/-pi.
Of course in most tasks (including immediate phonological memory) there would in fact be no need to decode a single measure of syllabic phase from the population activity. Representations of new words could be learned directly, exploiting temporal correspondences within distributed activity in sensory and motor populations (i.e., neurons encoding action at one part of the syllable cycle become linked to neurons encoding sounds associated with the same part of the cycle). Similarly, there would be no need to pair the output from cells with 90 degree offsets, and in fact one might expect to find a uniform distribution of phase tunings.
Exceptions to this would be tasks that involve making explicit judgements about syllable structure e.g., when counting syllables, or identifying syllable boundaries or p-centers. Even here, the pattern of activity across the population can represent the true complexity and occasional ambiguity of syllable structure within an utterance. These Some of these are discussed in more detail in the paper.