You Only Look for a Symbol Once: An Object Detector for Symbols and Regions in Documents
Abstract
We present YOLSO, a single stage object detector specialised for the detection of fixed size, non-uniform (e.g. hand-drawn or stamped) symbols in maps and other historical documents. Like YOLO, a single convolutional neural network predicts class probabilities and bounding boxes over a grid that exploits context surrounding an object of interest. However, our specialised approach differs from YOLO in several ways. We can assume symbols of a fixed scale and so need only predict bounding box centres, not dimensions. We can design the grid size and receptive field of a grid cell to be appropriate to the known scale of the symbols. Since maps have no meaningful boundary, we use a fully convolutional architecture applicable to any resolution and avoid introducing unwanted boundary dependency by using no padding. We extend the method to also perform coarse segmentation of regions indicated by symbols using the same single architecture. We evaluate our approach on the task of detecting symbols denoting free-standing trees and wooded regions in first edition Ordnance Survey maps and make the corresponding dataset as well as our implementation publicly available.
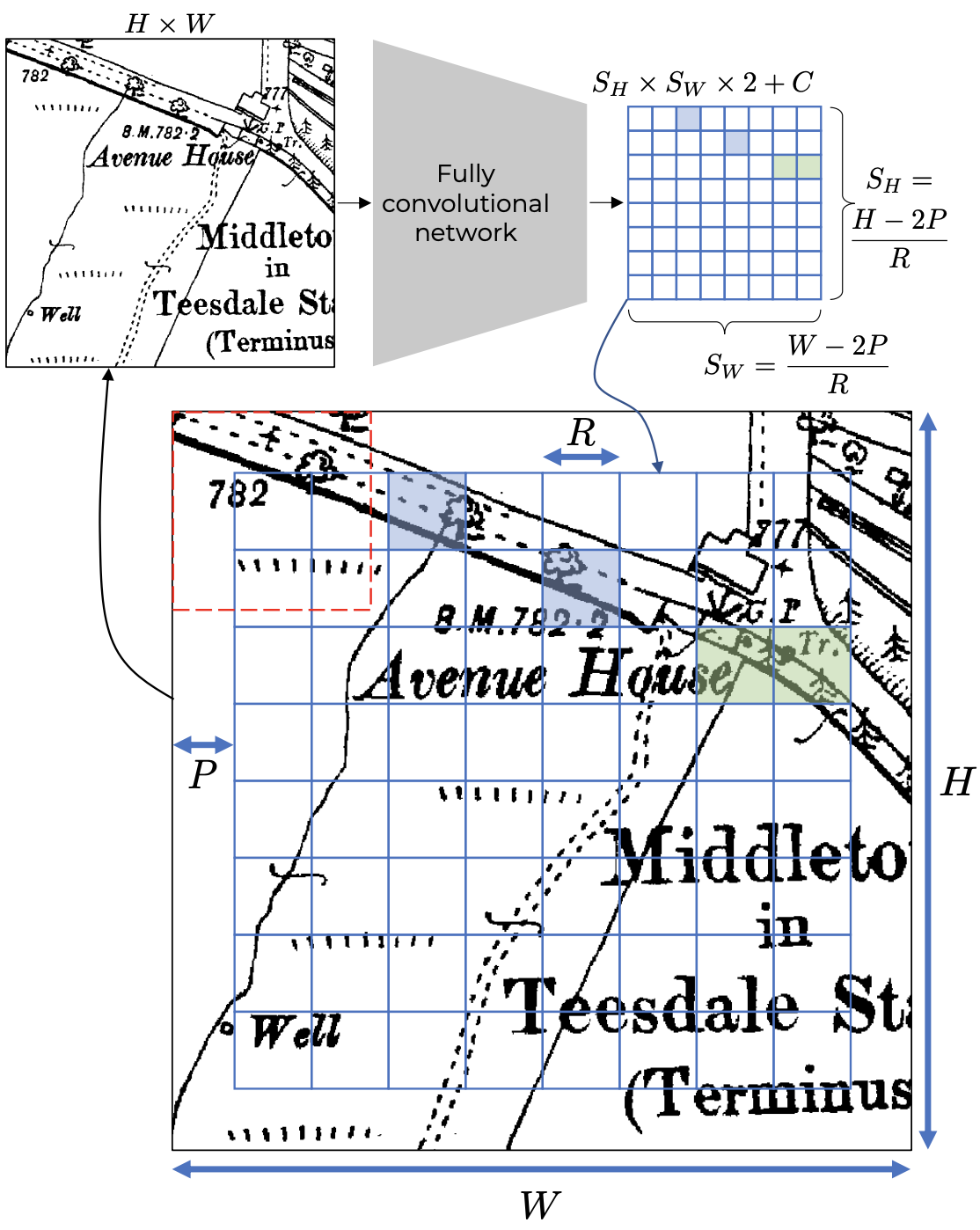
YOLSO is a fully convolutional network that takes as input an H × W image and outputs a (H−2P)/R × (W −2P)/R grid. Each cell in the output grid indicates whether the corresponding R × R region in the input image contains a symbol (class indicated by coloured fill) and, if so, the offset of the bounding box centre. The convolution layers use no padding and, hence, the receptive őeld of each grid cell (shown in red for the top left cell) is contained entirely within the original input image. To enable this, the input image must include a border of width P which ensures all output grid cells beneőt from local context and no boundary dependency is introduced.