Tarique Anwar

To date, my research has been around the area of Data Science along with Natural Language Processing (NLP), Machine (Deep) Learning, Artificial Intelligence (AI) and Complex Networks. I have worked/am working in the application domains of social media analytics, mental health, mis/dis-information, hate speech, criminal profiling, and transportation. Here is a summary of some of my major projects.
NLP and Explainable AI for Mental Health
Mental disorders, also called psychiatric disorders, are illnesses that impact our thoughts, feelings, emotions, and behaviors. Some of the common types are depression, anxiety, and eating disorders. They may influence our capacity to interact with others and operate on a daily basis. The longer a mental disorder lasts for, the more difficult it is to treat and recover from. Untreated mental disorders may lead to panic attacks or even suicide in the worst scenario. Early intervention typically yields greater results. It has been evident that natural disasters and pandemics adversely affect our mental health. The recent coronavirus disease 2019 (COVID-19) outbreak caused serious mental health issues, such as depression and anxiety, worldwide. Mental disorders are traditionally examined by psychologists and other specialists by face-to-face examination method. People typically tend to refrain from receiving such help until it gets severe. This in itself causes many unexamined cases which is extremely dangerous. Millions of people have social media accounts and they express their moods on social media. These massive and rich data are very helpful for predicting their mental health status at an early stage, enabling an early intervention. Extensive multidisciplinary research is currently being carried out in this direction. Some preliminary results suggest that applying NLP and interpretable deep learning on the posted textual contents and associated social networks is highly promising for detecting such disorders intelligently at an early stage. To this end, this research aims to develop novel NLP techniques and explainable AI models for intelligently detecting behaviors indicative of mental disorders.
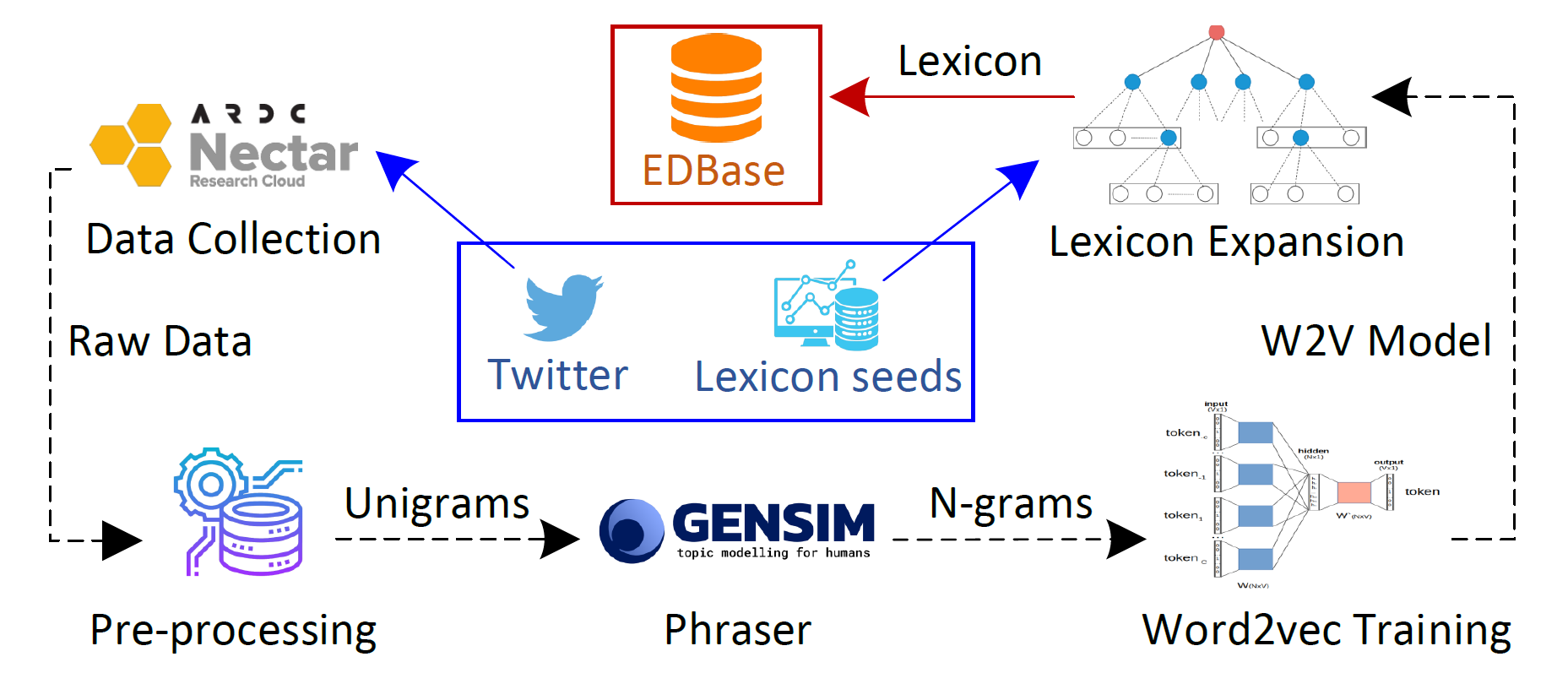
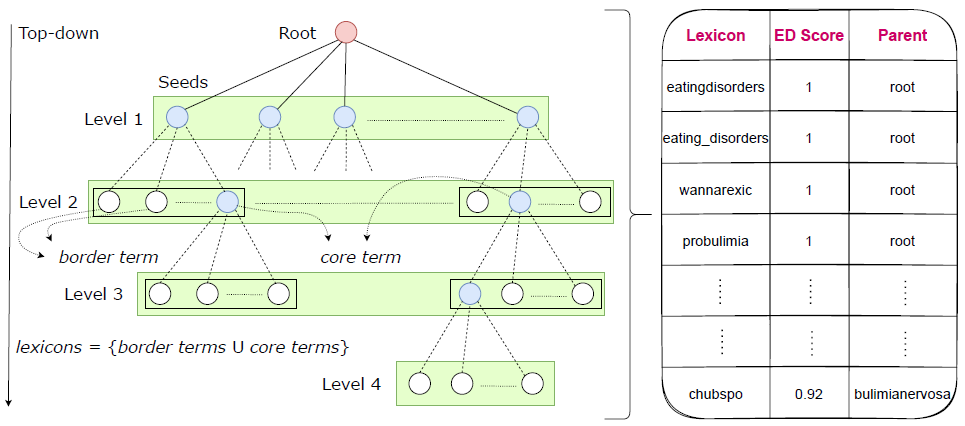
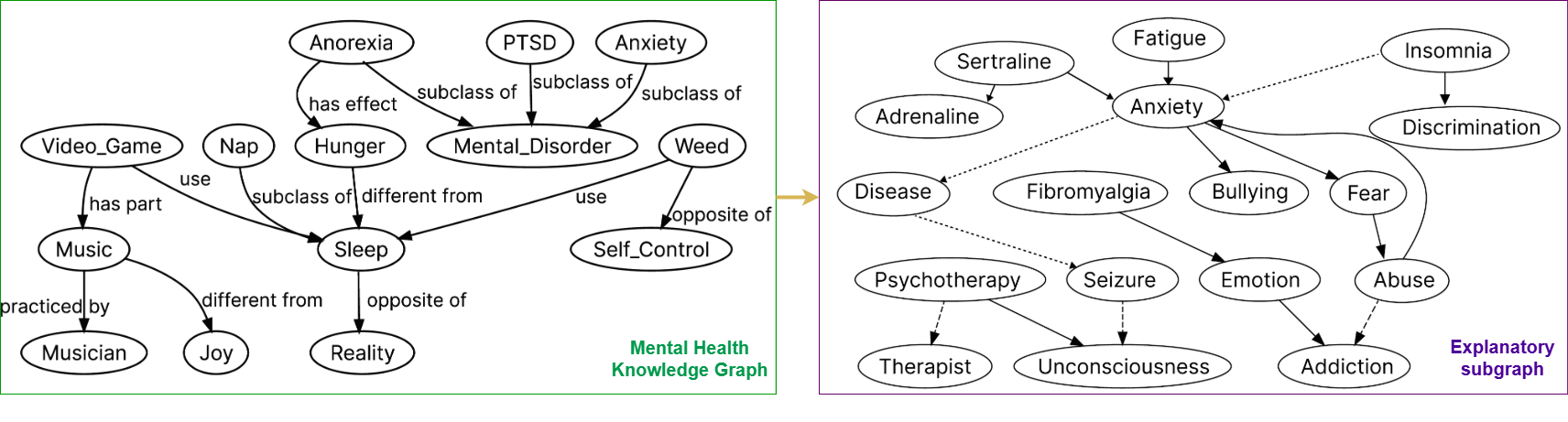
Collaborators: Tarique Anwar, Matthew Fuller-Tyszkiewicz, Mohammad Abuhasan, Chengfei Liu, Shreya Ghosh, Suku Sukunesan
Funding source(s): NHMRC MRFF (Australia), University of York (UK)
Outcomes*: [J.13], [J.14], [J.16], [J.17]
Mining Online Social Networks and Media for Public Good
The recent years have seen a rapid growth of online social media platforms such as Twitter, Facebook, Youtube, LinkedIn and Instagram. They provide a significant opportunity for people to connect with each other, share their updates, and remain informed about the happenings around the world. There are many important and interesting applications of making sense of big social network and media data. These applications could potentially bring huge benefits to the society, enterprises, and individuals. Social network and media data collected or aggregated from different platforms can be used directly to identify and track, crucial information related to the real society. It can also be used to gain insights into the social activities and latest happenings that take place around the world. With the help of domain experts such as cybersecurity specialists and psychologists, the online social data can be further enriched by the domain data. It will enable the domain experts to identify the underlying trends and patterns that are crucial for extracting some actionable knowledge beneficial for our real life problems. The aim of this research is to develop technical solutions for mining the social network and media contents with NLP, machine learning, and network science for solving realworld societal problems such as the detection of mis/dis-information, hate speech and infection sources.
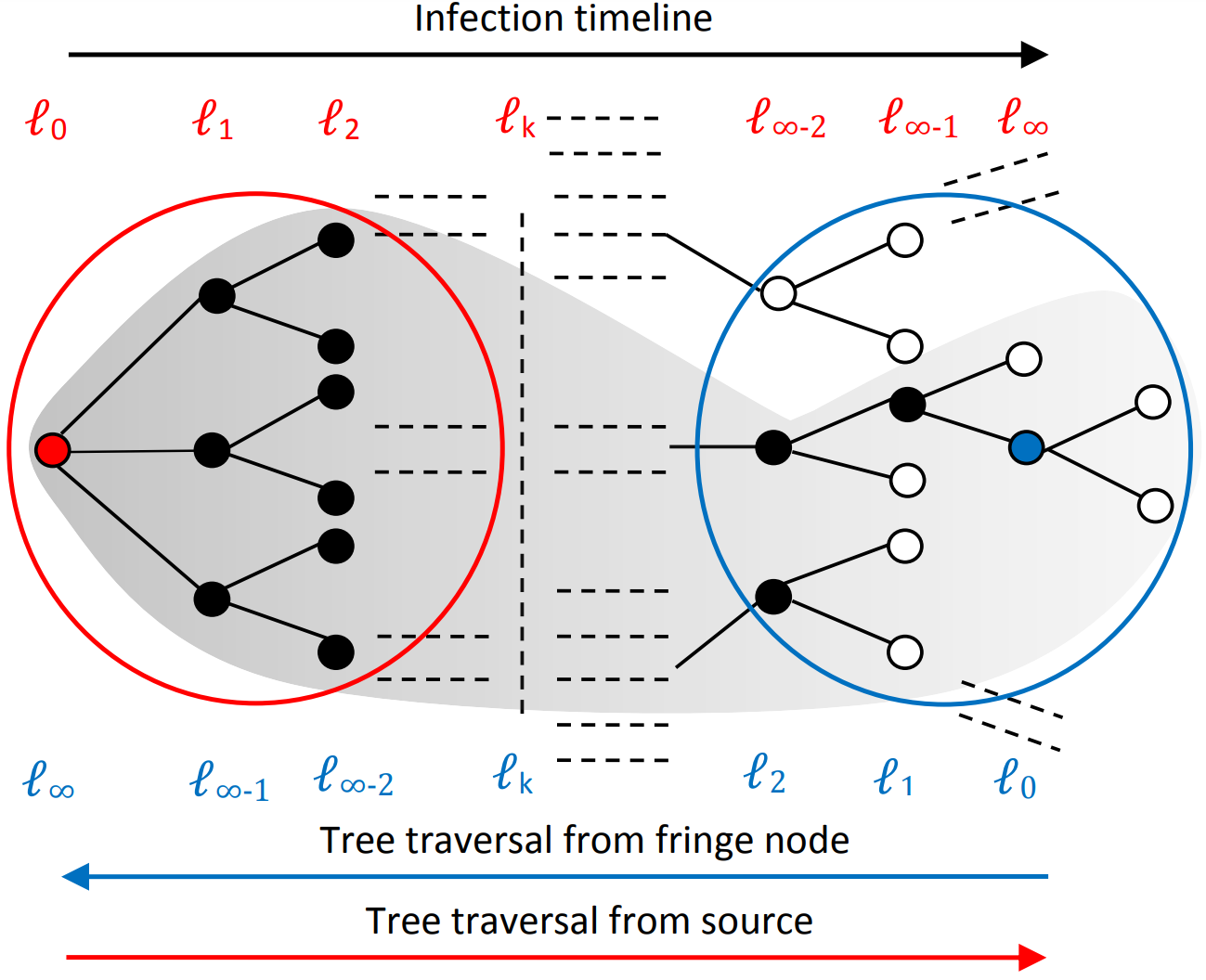
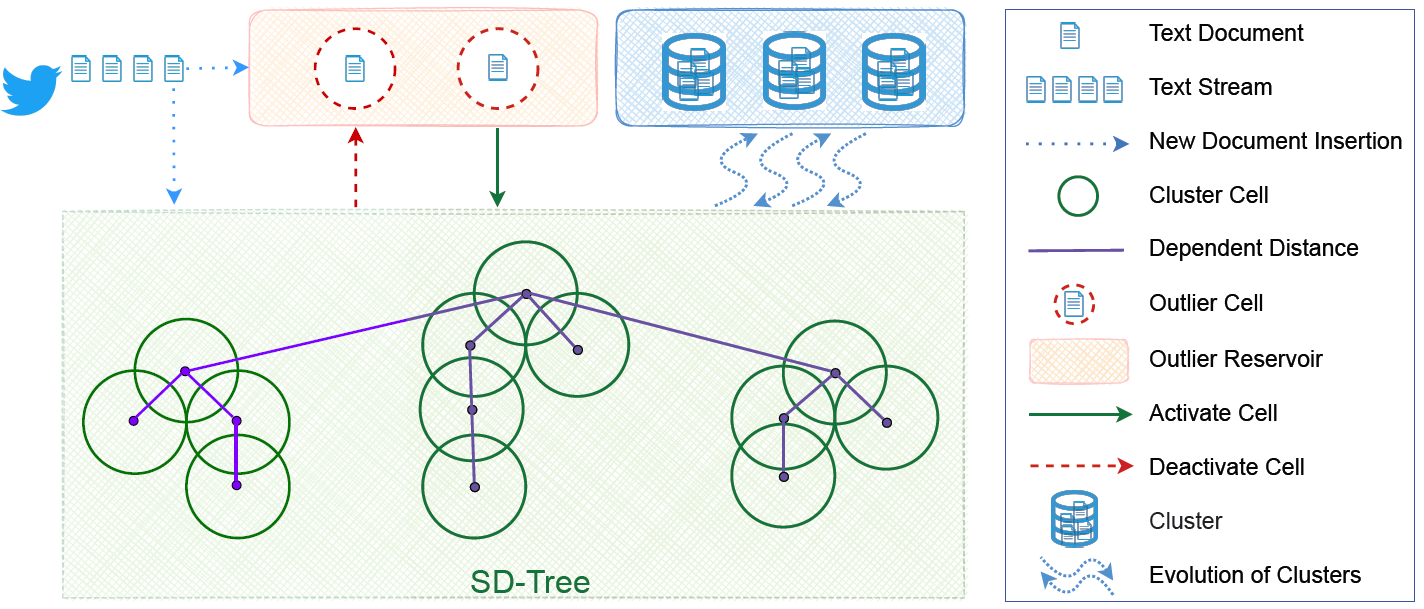
Collaborators: Tarique Anwar, Jian Yang, Jia Wu, Michael Sheng, Surya Nepal, Cecile Paris, Syed Shafat Ali, Ajay Rastogi, Mohd Fazil, Ashraf Kamal, Vineet Sejwal
Funding source(s): ISIRD, IIT Ropar, MHRD (India), CSIRO's Data61
Outcomes*: [C.4], [C.14], [C.15], [C.16], [J.10], [J.15], [J.18], [J.19]
Vehicular Transportation on Urban Road Networks
Smooth and hassle-free vehicular transportation on urban road networks is a key factor for smart and sustainable cities. Traffic congestion and thye demand of smart mobility services are some of the pressing issues of today. With the technological developments in the fields of GPS sensing and IT, and systems such as SCATS, SCOOT, and vehicle dispatching systems, we are able to collect huge volumes of traffic and trip data from urban road networks. Through sophisticated data mining and network analysis techniques, these data have the potential to aid in solving the crucial transportation problems. Nowadays, there is also a rising demand of smart mobility services such as ride-hailing and ride-sharing. These services require an efficient and effective system to be maintained for serving the incoming trip requests by dispatching available vehicles to the pickup points in a socially and economical profitable manner. The system faces the challenges of optimising the profits from different perspectives and efficiently serving the trip requests in realtime. This research aims at easing the pressing transportation issues of traffic congestion and on-demand mobility services with the help of data mining, machine learing, network analysis, and data management.
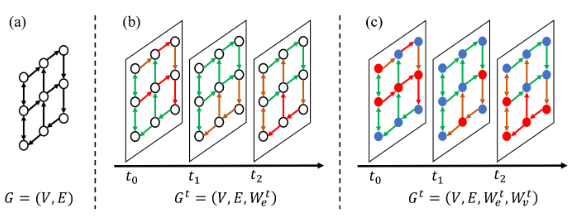
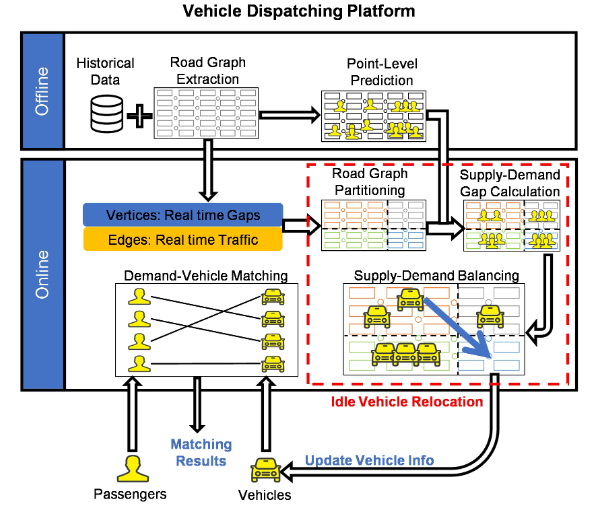
Collaborators: Tarique Anwar, Jian Yang, Jia Wu, Yang Guo, Chengfei Liu
Funding source(s): CSIRO's Data61, ARC Discover Project (Australia)
Outcomes*: [C.17], [C.18], [J.9], [J.12]
Spatial Partitioning of Road Traffic Networks and their Temporal Evolution (PhD thesis)
Urban areas generally attract people from all interior areas. According to the current global trend, people are rapidly migrating from rural towards urban areas for several reasons that include availing better livelihood services and seeking better employment opportunities. Consequently, the population of cities all over the world is increasing significantly, and thereby raising the mobility demands manyfold. This strongly motivates the research areas of urban planning and urban computing to develop innovative technologies and move towards smart and more sustainable cities. As most of the urban population travel daily or frequently for their work or studies, traffic congestion has become a very important practical problem. It is affecting the urban population directly by incurring extra cost on the fuel and extra time spent, and indirectly in many ways. An important concern in smart urbanization of our societies is the avoidance of such congestions and maintenance of a smooth transportation. While the infrastructure development is one direction to deal with this problem, the analysis of spatial traffic data to discover the congestion formation and propagation patterns, and apply them to optimize the traffic flow is another direction. The research on road traffic networks data analysis is growing with the problems like fastest route computation, traffic clustering, traffic prediction, emerging event detection, anomaly detection and bottleneck identification. To discover the congestion patterns, the continuous tracking of the spatiotemporal evolution of the traffic load leading to congestions is an important problem. The research on development of methods to identify the congested partitions effectively and track their evolution efficiently has been very limited so far. In my PhD thesis, we aim to capture the spatiotemporal evolution of urban road traffic networks. To this end, we propose technical methods to effectively partition road traffic networks in order to obtain the differently congested partitions at a point of time, and incrementally update those partitions in an efficient manner in order to track their evolution in real time.
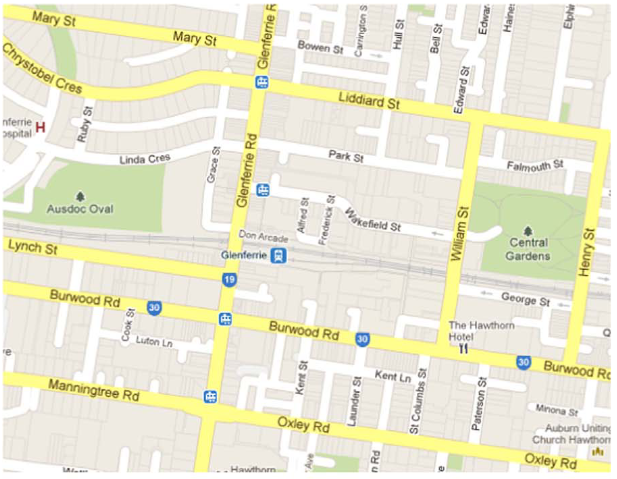
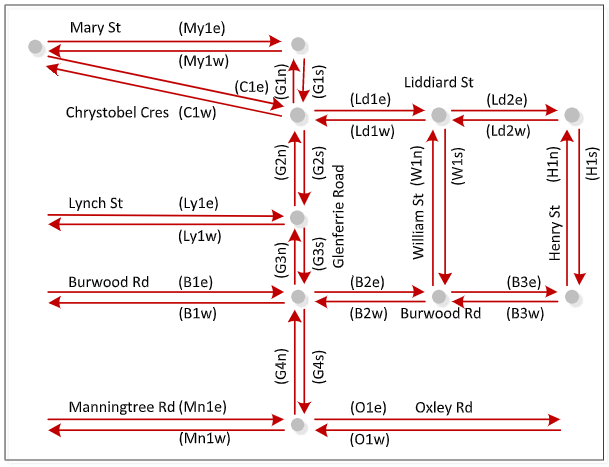
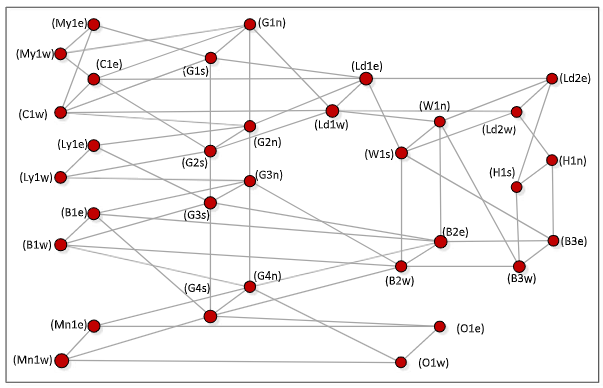
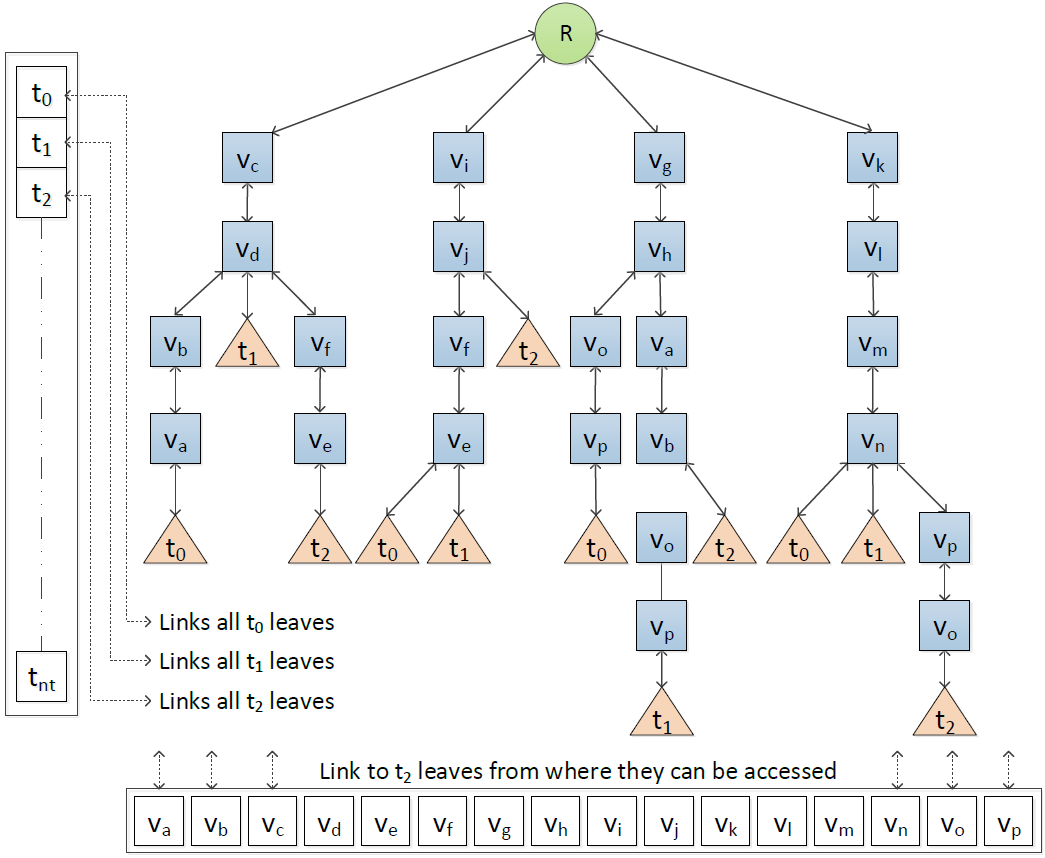
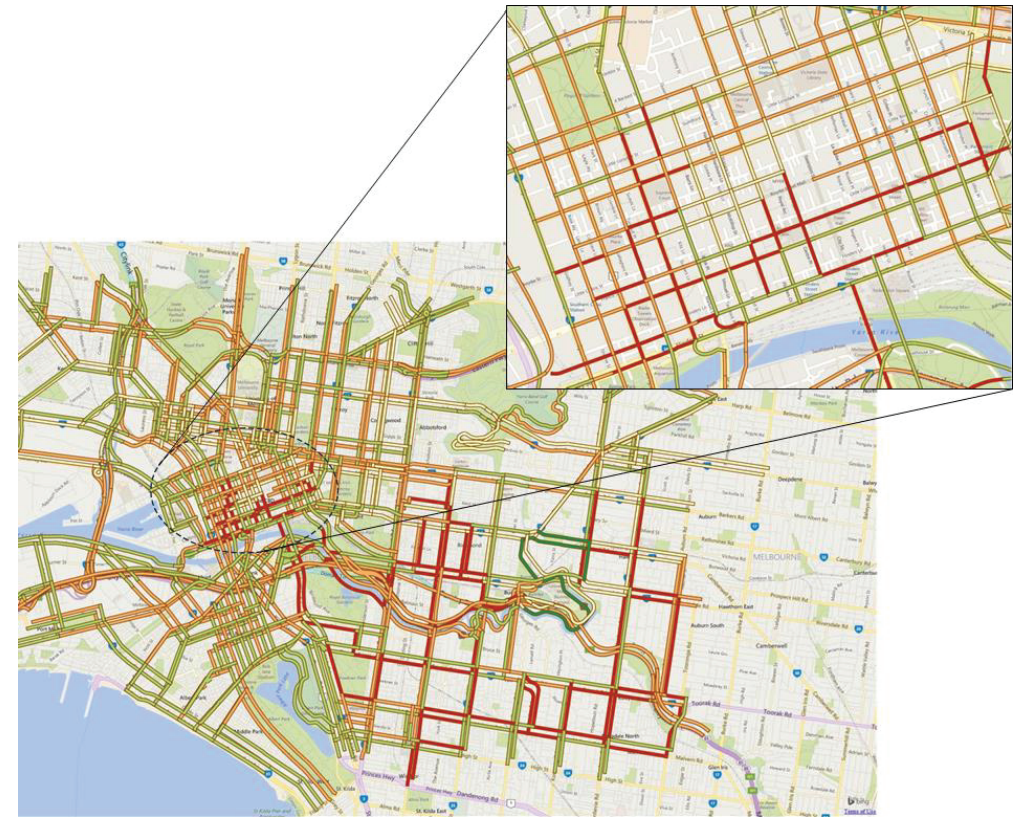
Collaborators: Tarique Anwar, Chengfei Liu, Hai L. Vu, Christopher Leckie, Timos Sellis, Serge P. Hoogendoorn
Funding source(s): NICTA / CSIRO's Data61 (Australia)
Outcomes*: [C.7], [C.8], [C.9], [C.11], [J.6], [J.7], [J.8], [J.11], [T.2]
Web Surveillance for Criminal Networks Identification and Monitoring
Many concealed anti-social organizations and their supporters use World Wide Web (WWW) for propaganda, training, recruitment and fund-raising. It is becoming a challenging task for intelligence agencies to track movement and activities of suspects around the globe. Due to huge amount of Web data and increasing cyber crimes, it has been realized by researchers that data mining techniques could be very useful for many national and international security initiatives. Primarily focusing on extraction of implicit and novel patterns (knowledge) from huge databases (structured data), data mining techniques have also proven to be very effective for analyzing unstructured (text documents) and semi-structured (Web documents) data. In the context of Web surveillance, data mining can be a potential means to identify terrorists and their activities through analyzing Web data and social networks evolved from communication networks including e-mails, enterprise portals, online forums, social networking sites like Facebook, Twitter, etc. In this project, we worked to design a knowledge-based Web surveillance framework that combines information retrieval, natural language processing and data mining techniques to identify criminals and their networks on the Web. The major components of our project are: (i) a data crawling and indexing process to retrieve focused multilingual Web contents, (ii) social network analysis to identify communities, leaders, (iii) sentiments analysis, (iv) in-depth web content mining to generate criminals profiles, (iv) in-depth web usage mining and link mining to track individual criminals and their linkages with the mined communities, (v) creation of a knowledge portal assist in national security. The system would provide necessary knowledge for the Saudi cyber law and security enforcement agencies to identify individuals who possibly can spread criminal ideologies, criminal profiling, criminal (social) network analysis, and visualization of criminal’s activities, linkages and relationships.
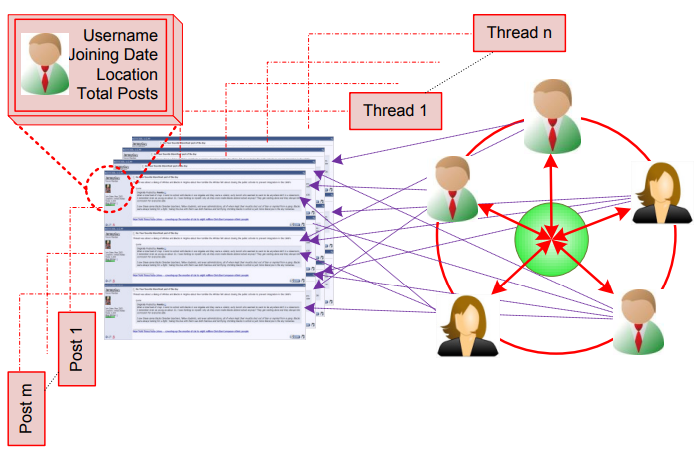

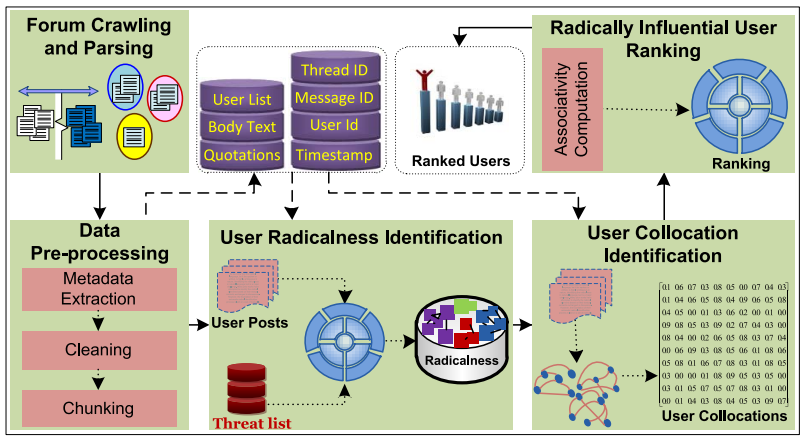
Collaborators: Tarique Anwar, Muhammad Abulaish, Khaled Alghathbar
Funding source(s): King Saud University, KACST NPST project 11-INF1594-02 (Saudi Arabia)
Outcomes*: [Ch.1], [C.1], [C.3], [C.5], [C.6], [J.3], [J.4], [J.5]
Datasets: Chat Log Dataset [This dataset can be dowloaded only for research purposes. Please cite the following paper, if you are using this dataset. "Tarique Anwar and Muhammad Abulaish, A Social Graph based Text Mining Framework for Chat Log Investigation, Digital Investigation, vol. 11 no. 4, pp. 349-362, Dec 2014"]
Keyphrase Extraction from Text Documents (Maters thesis)
A majority of useful information on the Web exists in the form of text, which are either unstructured or semi-structured in nature. The easy accessibility of electronic media and World Wide Web has conduced the exponential growth of text information overload. Thus even though there is no scarcity of information on the Web, locating, extracting and analyzing required information from this vast unstructured collection is a complex and challenging task. These complexities call for the need of an automatic text information processing system to identify and extract right information at right time for effective decision making. Keyphrases provide a semantic metadata that summarize and characterize documents and enable readers to quickly determine whether the given article is in the reader’s fields of interest. We worked to devise a light-weight machine learning approach for automatic keyphrase extraction using various lexical and semantic features mined from text documents, with the objective for its applicability to real time environments. The machine learning approach first builds a prediction model using training documents with known keyphrases, and then uses the model to find keyphrases in new documents.
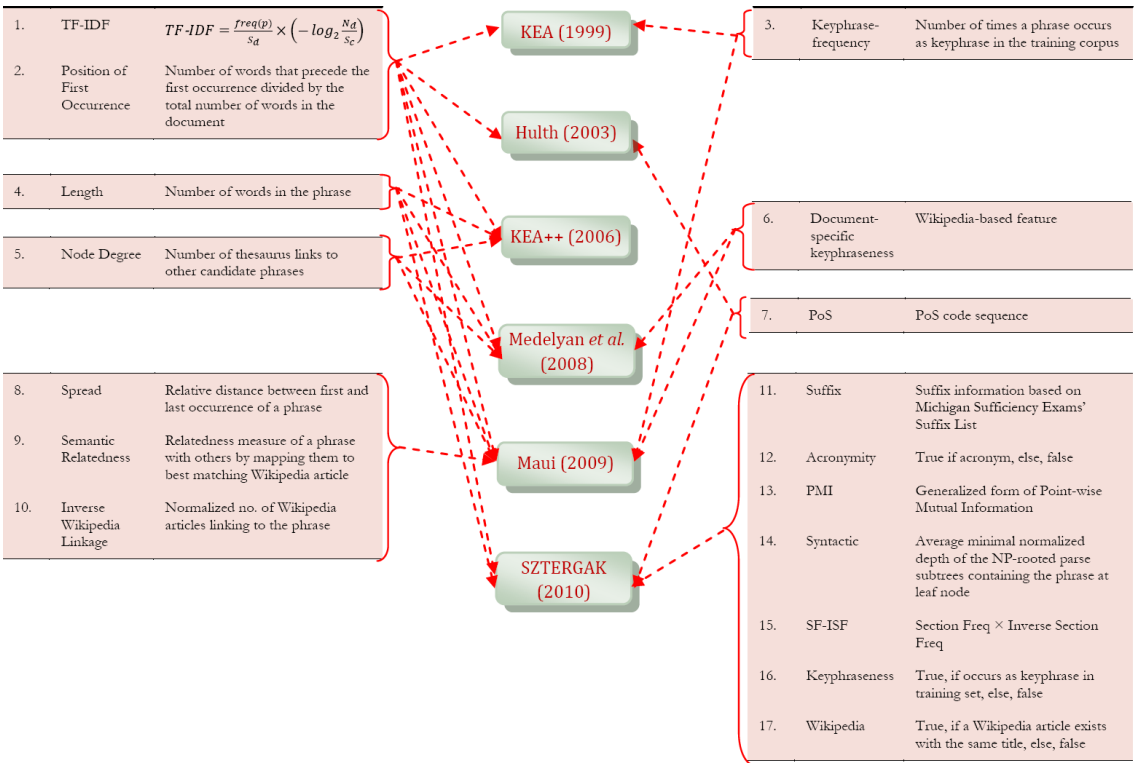
Collaborators: Tarique Anwar, Muhammad Abulaish
Outcomes*: [C.2], [J.1], [J.2], [T.1]
*PS: Please see the publications page to find the papers referred above.